
技术领域
本发明涉及家具领域,特别是涉及一种智能家居系统。
背景技术
智能家具产品打破了传统家具的组合模式,充分发挥了用户的主观创造性,外形尺寸、组合模式不再是家具生产厂家说的算,而是用户根据个人的喜好和家庭空间的实际情况,自由组合自由搭配。我们通过将家具功能拆分、单元化加工,每一个单元就是一件产品,产品可以通过产品的排列叠加进行组合。
目前,对智能家具设备的定义,正在从"通过自动和数控系统帮助控制家庭的灯光、温度、安全和娱乐",转向"通过用移动通信、平板电脑控制整个住宅产品全方位"。这不仅影响了人们的居住生态,也改变了人们的生活方式。
但目前社会上使用语音识别对智能家居系统的家具进行有效控制的产品并不多,而且推广度也不够大。语音识别家具现在没有办法大量推广的最主要原因是现有的语音识别算法还不够成熟,识别率和误识别率都没有办法达到大部分的智能家具要求,导致语音识别的智能家具的性能较差。
发明内容
为了解决上述技术问题,本发明提供一种智能家居系统。
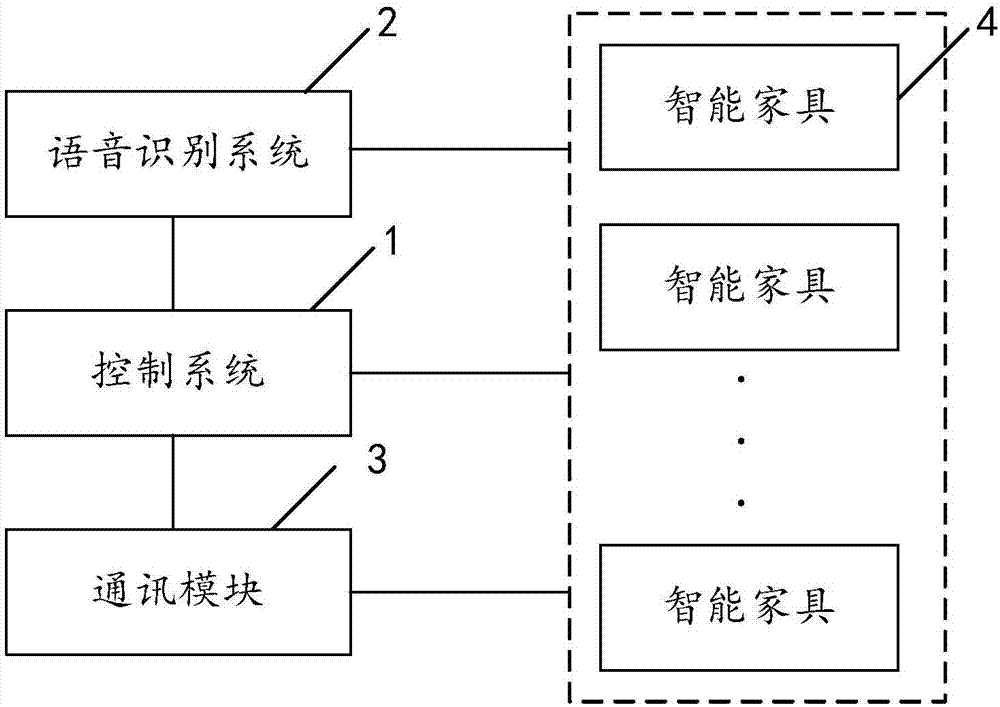
一种智能家居系统,包括控制系统、语音识别系统、通讯模块、多个智能家具和电源线,所述控制系统、语音识别系统、通讯模块和多个智能家具均与电源线连接,所述语音识别系统、通讯模块和多个智能家具均与控制系统连接并受控于所述控制系统;所述语音识别系统与每个智能家具连接;所述语音识别系统包括依次连接的语音信号采集单元、语音预处理单元、语音识别单元和传输单元。
进一步的,所述语音信号采集单元用于采集语音信息,并将采集到的语音信息发送给所述语音预处理单元;所述语音信号采集单元为麦克风。
进一步的,所述语音预处理单元对接收的语音信息进行预滤波、采样、量化、加窗、预加重、端点检测和去噪处理后得到预处理后的语音数据,并将得到的所述预处理后的语音数据发送给所述语音识别单元;
所述语音识别单元包括特征提取单元、比较单元、输出单元和存储单元,所述存储单元用于存储对照语音数据,
所述特征提取单元用于提取所述语音预处理单元处理后的语音数据中的语音特征参数值,根据所述语音特征参数值生成待比较语音数据;
所述比较单元用于将待比较语音数据与所述对照语音数据进行比较并生成比较结果,
所述输出单元用于根据所述比较结果,确定所述比较语音数据对应的语音含义,并根据所述语音含义输出相应的识别后的语音信息;
所述传输单元将所述识别后的语音信息传输给控制系统;
所述控制系统将识别后的语音信息解析成相应的控制指令,并将控制指令通过通讯模块传输给相应的智能家具。
进一步的,语音预处理单元执行预加重包括:
将得到的语音序列通过预设的预加重滤波器以消除所述语音序列中的低频干扰。
语音预处理单元执行端点检测包括:将预加重后的语音序列进行分帧处理;通过第一预设检测算法判断每帧数据中是否存在语音的起始端点;若存在,则获取语音的起始端点所在的帧序号;通过第二预设检测算法判断排序在所述语音的起始端点所在的帧序号之后的每帧数据中是否存在语音的终止端点,若存在,则获取语音的终止端点所在的帧序号。
其中所述第一预设检测算法包括:对于每一帧的帧数据,判断所述帧数据的能量是否大于预设的能量阈值;所述能量值为帧数据中采样点的采样值的绝对值的平方和;若是,则计算所述帧数据的过零数,只有当所述帧数据中两个相邻采样点的符号相反并且幅值差的绝对值超过过零阈值时,判定出现一次过零;进一步判断所述过零数是否大于预设的过零数阈值,若是,则判定所述帧数据中存在语音的起始端点。
所述第二预设检测算法包括:对于每一帧的帧数据,判断所述帧数据的能量是否大于预设的自适应能量阈值;所述能量值为帧数据中采样点的采样值的绝对值的平方和;所述自适应能量阈值为第一能量阈值、第二能量阈值、第三能量阈值、第四能量阈值和第五能量阈值的加权平均值;若是,则所述帧数据包括语音的终止端点。
其中,所述第一能量阈值为最大短时能量的十分之一;所述第二能量阈值为短时能量的中位数的十分之一;所述第三能量阈值为最小短时能量的十倍;所述第四能量阈值为第一帧的短时能量的四倍;所述第五能量阈值为前三帧的平均短时能量的七倍;
所述最大短时能量、短时能量的中位数和最小短时能量均来自预设的语音训练集;所述第四能量阈值和第五能量阈值与语音预处理单元当下正在处理的语音帧数据有关。
进一步的,所述第一能量阈值、第二能量阈值、第三能量阈值、第四能量阈值和第五能量阈值的对应权值根据所述语音训练集的训练结果进行自动调整。
进一步的,语音预处理单元执行去噪处理包括:
S1:获取语音起始端点和语音终止端点之间的帧数据;
S2:选择合适的小波基和分解层数,对帧数据进行正交小波变换,得到相应的各尺度分解系数;
S3:选择合适的去噪阈值及阈值函数,对所述各尺度分解系数进行处理,得到其对应的估计小波系数;
S4:进行小波重构,得到去噪后的帧数据。
其中,所述去噪阈值的设定方法包括:从预设的语音训练集中挑选多个目标语音序列;获取每个目标语音序列对应的分阈值;将各个分阈值的求和值作为所述去噪阈值。
所述获取每个目标语音序列对应的分阈值包括:
得到目标语音序列的的升序序列y(k);
得到所述升序序列对应的第一目标序列y1(k)和第二目标序列y2(k);
根据公式计算分阈值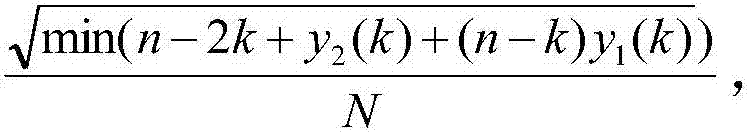 n为目标序列中的元素个数,k为目标序列中的各个元素的下标,N是目标语音序列的个数。
n为目标序列中的元素个数,k为目标序列中的各个元素的下标,N是目标语音序列的个数。
其中,所述第一目标序列y1(k)为y2(k),第二目标序列y2(k)为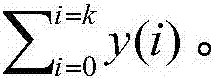
本发明的有益效果是:本发明提供一种智能家居系统,包括控制系统、语音识别系统、通讯模块、多个智能家具和电源线,所述语音识别系统、通讯模块和多个智能家具均与控制系统连接并受控于所述控制系统;所述语音识别系统与每个智能家具连接;从而方便用户使用智能家具,为智能家居提供方便。
附图说明
图1是本发明的一种智能家居系统的结构示意图;
图2是本发明的语音识别系统的结构示意图;
图3是本发明的语音识别单元的结构示意图;
图4是本发明的语音预处理单元执行去噪处理示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图1-4对本发明作进一步地详细描述。
一种智能家居系统,包括控制系统1、语音识别系统2、通讯模块3、多个智能家具4和电源线,所述控制系统、语音识别系统、通讯模块和多个智能家具均与电源线连接,所述语音识别系统2、通讯模块3和多个智能家具4均与控制系统1连接并受控于所述控制系统1;所述语音识别系统与每个智能家具连接;所述语音识别系统包括依次连接的语音信号采集单元21、语音预处理单元22、语音识别单元23和传输单元24。
进一步的,所述语音信号采集单元用于采集语音信息,并将采集到的语音信息发送给所述语音预处理单元;所述语音信号采集单元为麦克风。
进一步的,所述语音预处理单元对接收的语音信息进行预滤波、采样、量化、加窗、预加重、端点检测和去噪处理后得到预处理后的语音数据,并将得到的所述预处理后的语音数据发送给所述语音识别单元;
所述语音识别单元23包括特征提取单元231、比较单元232、输出单元233和存储单元234,所述存储单元用于存储对照语音数据,
所述特征提取单元用于提取所述语音预处理单元处理后的语音数据中的语音特征参数值,根据所述语音特征参数值生成待比较语音数据;
所述比较单元用于将待比较语音数据与所述对照语音数据进行比较并生成比较结果,
所述输出单元用于根据所述比较结果,确定所述比较语音数据对应的语音含义,并根据所述语音含义输出相应的识别后的语音信息;
所述传输单元将所述识别后的语音信息传输给控制系统;
所述控制系统将识别后的语音信息解析成相应的控制指令,并将控制指令通过通讯模块传输给相应的智能家具。
进一步的,语音预处理单元执行预加重包括:
将得到的语音序列通过预设的预加重滤波器以消除所述语音序列中的低频干扰。
语音预处理单元执行端点检测包括:将预加重后的语音序列进行分帧处理;通过第一预设检测算法判断每帧数据中是否存在语音的起始端点;若存在,则获取语音的起始端点所在的帧序号;通过第二预设检测算法判断排序在所述语音的起始端点所在的帧序号之后的每帧数据中是否存在语音的终止端点,若存在,则获取语音的终止端点所在的帧序号。
其中所述第一预设检测算法包括:对于每一帧的帧数据,判断所述帧数据的能量是否大于预设的能量阈值;所述能量值为帧数据中采样点的采样值的绝对值的平方和;若是,则计算所述帧数据的过零数,只有当所述帧数据中两个相邻采样点的符号相反并且幅值差的绝对值超过过零阈值时,判定出现一次过零;进一步判断所述过零数是否大于预设的过零数阈值,若是,则判定所述帧数据中存在语音的起始端点。
所述第二预设检测算法包括:对于每一帧的帧数据,判断所述帧数据的能量是否大于预设的自适应能量阈值;所述能量值为帧数据中采样点的采样值的绝对值的平方和;所述自适应能量阈值为第一能量阈值、第二能量阈值、第三能量阈值、第四能量阈值和第五能量阈值的加权平均值;若是,则所述帧数据包括语音的终止端点。
其中,所述第一能量阈值为最大短时能量的十分之一;所述第二能量阈值为短时能量的中位数的十分之一;所述第三能量阈值为最小短时能量的十倍;所述第四能量阈值为第一帧的短时能量的四倍;所述第五能量阈值为前三帧的平均短时能量的七倍;
所述最大短时能量、短时能量的中位数和最小短时能量均来自预设的语音训练集;所述第四能量阈值和第五能量阈值与语音预处理单元当下正在处理的语音帧数据有关。
进一步的,所述第一能量阈值、第二能量阈值、第三能量阈值、第四能量阈值和第五能量阈值的对应权值根据所述语音训练集的训练结果进行自动调整。
进一步的,语音预处理单元执行去噪处理包括:
S1:获取语音起始端点和语音终止端点之间的帧数据;
S2:选择合适的小波基和分解层数,对帧数据进行正交小波变换,得到相应的各尺度分解系数;
S3:选择合适的去噪阈值及阈值函数,对所述各尺度分解系数进行处理,得到其对应的估计小波系数;
S4:进行小波重构,得到去噪后的帧数据。
其中,所述去噪阈值的设定方法包括:从预设的语音训练集中挑选多个目标语音序列;获取每个目标语音序列对应的分阈值;将各个分阈值的求和值作为所述去噪阈值。
所述获取每个目标语音序列对应的分阈值包括:
得到目标语音序列的的升序序列y(k);
得到所述升序序列对应的第一目标序列y1(k)和第二目标序列y2(k);
根据公式计算分阈值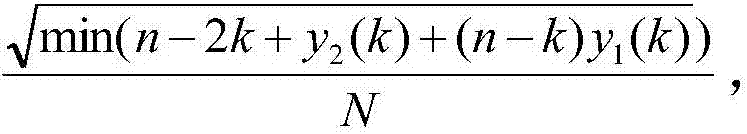 n为目标序列中的元素个数,k为目标序列中的各个元素的下标,N是目标语音序列的个数。
n为目标序列中的元素个数,k为目标序列中的各个元素的下标,N是目标语音序列的个数。
其中,所述第一目标序列y1(k)为y2(k),第二目标序列y2(k)为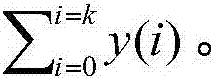
以上所揭露的仅为本发明较佳实施例而已,当然不能以此来限定本发明之权利范围,因此依本发明权利要求所作的等同变化,仍属本发明所涵盖的范围。
