技术领域
本发明涉及一种图像处理方法,尤其是涉及一种深度图像的预处理方法。
背景技术
三维视频(Three-Dimensional Video,3DV)是一种先进的视觉模式,它使人们在屏幕上观看图像时富有立体感和沉浸感,可以满足人们从不同角度观看三维(3D)场景的需求。典型的三维视频系统如图1所示,其主要包括视频捕获、视频编码、传输解码、虚拟视点绘制和交互显示等模块。
多视点视频加深度(multi-view video plus depth,MVD)是目前ISO/MPEG推荐采用的3D场景信息表示方式。MVD数据在多视点彩色图像基础上增加了对应视点的深度信息,深度信息的获取目前主要有两种基本途径:1)通过深度相机获取;2)通过算法从普通的二维(2D)视频中生成深度信息。基于深度图像的绘制(Depth Image BasedRendering,DIBR)是一种利用参考视点的彩色图像所对应的深度图像绘制生成虚拟视点图像的方法,其通过利用参考视点的彩色图像及该参考视点的彩色图像中的每个像素点对应的深度信息来合成三维场景的虚拟视点图像。由于DIBR将场景的深度信息引入到虚拟视点图像绘制中,从而大大减少了虚拟视点图像绘制所需的参考视点的数目。
与彩色图像相比,深度图像的纹理简单,其包括较多的平坦区域,但由于深度图像获取算法的局限性,因此深度图像普遍存在时间连续性差、深度不连续等问题。目前已提出了一些针对深度图像的预处理方法,如对称高斯滤波和非对称高斯滤波等算法,然而这些预处理方法考虑更多的是如何提升编码的性能,而深度图像用于辅助DIBR和3D显示,并非直接用于观看,因此,如何对深度图像进行预处理,在保证编码效率的前提下使得深度失真对虚拟视点图像绘制的影响以及对3D显示的主观感知质量的影响最小,是目前对深度图像进行预处理需要解决的问题。
发明内容
本发明所要解决的技术问题是提供一种在保持虚拟视点图像绘制性能的基础上,能够大大提高深度图像的压缩效率的深度图像预处理方法。
本发明解决上述技术问题所采用的技术方案为:一种深度图像的预处理方法,其特征在于包括以下步骤:
①获取t时刻的K个参考视点的K幅颜色空间为YUV的彩色图像及其对应的K幅深度图像,将t时刻的第k个参考视点的彩色图像记为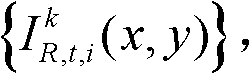 将t时刻的第k个参考视点的深度图像记为
将t时刻的第k个参考视点的深度图像记为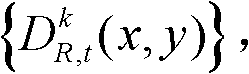 其中,1≤k≤K,k的初始值为1,i=1,2,3分别表示YUV颜色空间的三个分量,YUV颜色空间的第1个分量为亮度分量并记为Y、第2个分量为第一色度分量并记为U及第3个分量为第二色度分量并记为V,(x,y)表示彩色图像或深度图像中像素点的坐标位置,1≤x≤W,1≤y≤H,W表示彩色图像或深度图像的宽度,H表示彩色图像或深度图像的高度,
其中,1≤k≤K,k的初始值为1,i=1,2,3分别表示YUV颜色空间的三个分量,YUV颜色空间的第1个分量为亮度分量并记为Y、第2个分量为第一色度分量并记为U及第3个分量为第二色度分量并记为V,(x,y)表示彩色图像或深度图像中像素点的坐标位置,1≤x≤W,1≤y≤H,W表示彩色图像或深度图像的宽度,H表示彩色图像或深度图像的高度,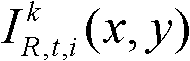 表示t时刻的第k个参考视点的彩色图像
表示t时刻的第k个参考视点的彩色图像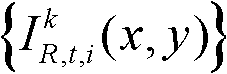 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,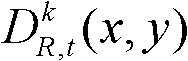 表示t时刻的第k个参考视点的深度图像
表示t时刻的第k个参考视点的深度图像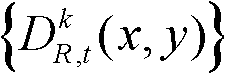 中坐标位置为(x,y)的像素点的深度值;
中坐标位置为(x,y)的像素点的深度值;
②利用人类视觉对背景光照和纹理的视觉掩蔽效应,提取出t时刻的第k个参考视点的彩色图像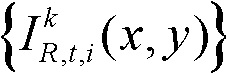 的最小可察觉变化步长图像,记为
的最小可察觉变化步长图像,记为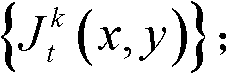
③根据t时刻的第k个参考视点的彩色图像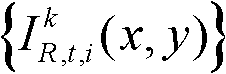 的最小可察觉变化步长图像
的最小可察觉变化步长图像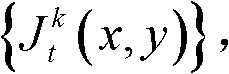 提取出t时刻的第k个参考视点的深度图像
提取出t时刻的第k个参考视点的深度图像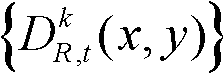 的最大可容忍失真分布图像,记为
的最大可容忍失真分布图像,记为
④根据t时刻的第k个参考视点的深度图像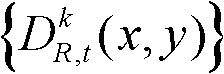 的最大可容忍失真分布图像
的最大可容忍失真分布图像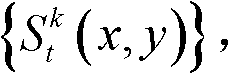 将t时刻的第k个参考视点的深度图像
将t时刻的第k个参考视点的深度图像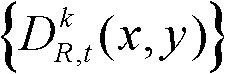 分割成置信内容区域和非置信内容区域;
分割成置信内容区域和非置信内容区域;
⑤利用两组不同滤波强度的双向滤波器分别对t时刻的第k个参考视点的深度图像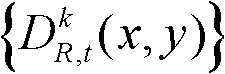 的置信内容区域和非置信内容区域中的各个像素点的深度值进行滤波处理,得到滤波后的深度图像,记为
的置信内容区域和非置信内容区域中的各个像素点的深度值进行滤波处理,得到滤波后的深度图像,记为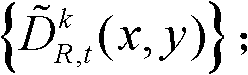
⑥令k′=k+1,k=k′,返回步骤②继续执行,直至得到t时刻的K个参考视点的K幅滤波后的深度图像,K幅滤波后的深度图像用集合表示为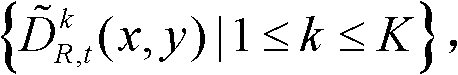 其中,k′的初始值为0;
其中,k′的初始值为0;
⑦根据设定的编码预测结构分别对t时刻的K个参考视点的K幅颜色空间为YUV的彩色图像及其对应的K幅滤波后的深度图像进行编码,再将编码后的K幅彩色图像及其对应的K幅深度图像经网络传输给解码端;
⑧在解码端对编码后的K幅彩色图像及其对应的K幅深度图像进行解码,获得解码后的t时刻的K个参考视点的K幅彩色图像及其对应的K幅深度图像,采用基于深度图像的绘制得到虚拟视点图像。
所述的步骤②包括以下具体步骤:
②-1、计算t时刻的第k个参考视点的彩色图像 的背景光照的视觉掩蔽效应的可视化阈值集合,记为{Tl(x,y)},
的背景光照的视觉掩蔽效应的可视化阈值集合,记为{Tl(x,y)},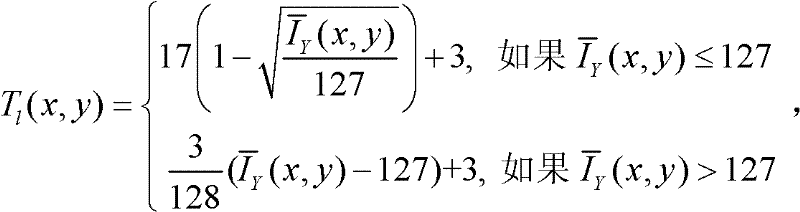 其中,
其中,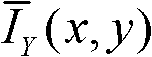 表示t时刻的第k个参考视点的彩色图像
表示t时刻的第k个参考视点的彩色图像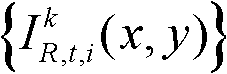 中以坐标位置为(x,y)的像素点为中心的5×5窗口内的所有像素点的亮度平均值;
中以坐标位置为(x,y)的像素点为中心的5×5窗口内的所有像素点的亮度平均值;
②-2、计算t时刻的第k个参考视点的彩色图像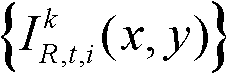 的纹理的视觉掩蔽效应的可视化阈值集合,记为
的纹理的视觉掩蔽效应的可视化阈值集合,记为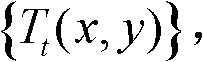 Tt(x,y)=η×G(x,y)×We(x,y),其中,η为大于0的控制因子,G(x,y)表示对t时刻的第k个参考视点的彩色图像
Tt(x,y)=η×G(x,y)×We(x,y),其中,η为大于0的控制因子,G(x,y)表示对t时刻的第k个参考视点的彩色图像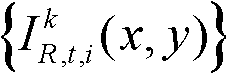 中坐标位置为(x,y)的像素点进行定向高通滤波得到的最大加权平均值,We(x,y)表示对t时刻的第k个参考视点的彩色图像
中坐标位置为(x,y)的像素点进行定向高通滤波得到的最大加权平均值,We(x,y)表示对t时刻的第k个参考视点的彩色图像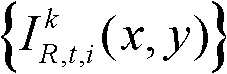 的边缘图像中坐标位置为(x,y)的像素点进行高斯低通滤波得到的边缘加权值;
的边缘图像中坐标位置为(x,y)的像素点进行高斯低通滤波得到的边缘加权值;
②-3、对t时刻的第k个参考视点的彩色图像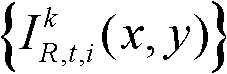 的背景光照的视觉掩蔽效应的可视化阈值集合{Tl(x,y)}和纹理的视觉掩蔽效应的可视化阈值集合{Tt(x,y)}进行融合,得到t时刻的第k个参考视点的彩色图像
的背景光照的视觉掩蔽效应的可视化阈值集合{Tl(x,y)}和纹理的视觉掩蔽效应的可视化阈值集合{Tt(x,y)}进行融合,得到t时刻的第k个参考视点的彩色图像 的最小可察觉变化步长图像,记为
的最小可察觉变化步长图像,记为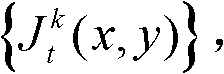 其中,Cl,t表示控制背景光照和纹理的视觉掩蔽效应重叠影响的参数,0<Cl,t<1,min{}为取最小值函数。
其中,Cl,t表示控制背景光照和纹理的视觉掩蔽效应重叠影响的参数,0<Cl,t<1,min{}为取最小值函数。
所述的步骤③包括以下具体步骤:
③-1、定义t时刻的第k个参考视点的深度图像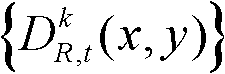 中当前正在处理的像素点为当前像素点;
中当前正在处理的像素点为当前像素点;
③-2、将当前像素点的坐标位置记为(x1,y1),将与当前像素点水平相邻的像素点的坐标位置记为(x1+Δx,y1),计算当前像素点和与其水平相邻的像素点之间的颜色距离,记为Ψ(x1+Δx,y1),计算当前像素点和与其水平相邻的像素点之间的深度距离,记为Φ(x1+Δx,y1),其中,Δx表示水平偏移量,-W′≤Δx<0或0<Δx≤W′,W′为最大水平偏移量,“||”为绝对值符号, 表示t时刻的第k个参考视点的彩色图像
表示t时刻的第k个参考视点的彩色图像 中坐标位置为(x1,y1)的像素点的Y分量的值,
中坐标位置为(x1,y1)的像素点的Y分量的值,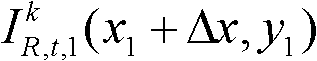 表示t时刻的第k个参考视点的彩色图像
表示t时刻的第k个参考视点的彩色图像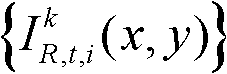 中坐标位置为(x1+Δx,y1)的像素点的Y分量的值,
中坐标位置为(x1+Δx,y1)的像素点的Y分量的值,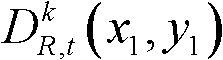 表示t时刻的第k个参考视点的深度图像
表示t时刻的第k个参考视点的深度图像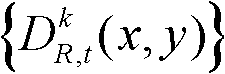 中坐标位置为(x1,y1)的像素点的深度值,
中坐标位置为(x1,y1)的像素点的深度值,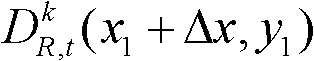 表示t时刻的第k个参考视点的深度图像
表示t时刻的第k个参考视点的深度图像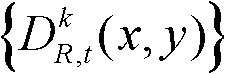 中坐标位置为(x1+Δx,y1)的像素点的深度值;
中坐标位置为(x1+Δx,y1)的像素点的深度值;
③-3、从当前像素点的左方向水平偏移量集合{ΔxL|-W′≤ΔxL≤-1}中任取一个ΔxL′,如果 且Φ(x1+ΔxL′,y1)≤T1同时成立,则认为ΔxL′为当前像素点的一个左方向可容忍失真值;采用相同的方法计算当前像素点的左方向水平偏移量集合中的所有左方向可容忍失真值,再从所有左方向可容忍失真值中找出绝对值最大的左方向可容忍失真值,将绝对值最大的左方向可容忍失真值作为当前像素点的左方向最大可容忍失真值,记为ΔL(x1,y1),其中,Ψ(x1+ΔxL′,y1)表示当前像素点和坐标位置为(x1+ΔxL′,y1)的像素点之间的颜色距离,
且Φ(x1+ΔxL′,y1)≤T1同时成立,则认为ΔxL′为当前像素点的一个左方向可容忍失真值;采用相同的方法计算当前像素点的左方向水平偏移量集合中的所有左方向可容忍失真值,再从所有左方向可容忍失真值中找出绝对值最大的左方向可容忍失真值,将绝对值最大的左方向可容忍失真值作为当前像素点的左方向最大可容忍失真值,记为ΔL(x1,y1),其中,Ψ(x1+ΔxL′,y1)表示当前像素点和坐标位置为(x1+ΔxL′,y1)的像素点之间的颜色距离,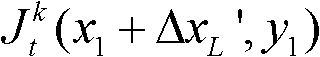 表示
表示 中坐标位置为(x1+ΔxL′,y1)的像素点的最小可察觉变化步长值,Φ(x1+ΔxL′,y1)表示当前像素点和坐标位置为(x1+ΔxL′,y1)的像素点之间的深度距离,T1为深度敏感性阈值;
中坐标位置为(x1+ΔxL′,y1)的像素点的最小可察觉变化步长值,Φ(x1+ΔxL′,y1)表示当前像素点和坐标位置为(x1+ΔxL′,y1)的像素点之间的深度距离,T1为深度敏感性阈值;
③-4、从当前像素点的右方向水平偏移量集合{ΔxR|1≤ΔxR≤W′}中任取一个ΔxR′,如果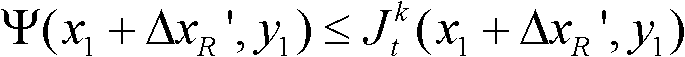 且Φ(x1+ΔxR′,y1)≤T1同时成立,则认为ΔxR′为当前像素点的一个右方向可容忍失真值;采用相同的方法计算当前像素点的右方向水平偏移量集合中的所有右方向可容忍失真值,再从所有右方向可容忍失真值中找出绝对值最大的右方向可容忍失真值,将绝对值最大的右方向可容忍失真值作为当前像素点的右方向最大可容忍失真值,记为ΔR(x1,y1),其中,Ψ(x1+ΔxR′,y1)表示当前像素点和坐标位置为(x1+ΔxR′,y1)的像素点之间的颜色距离,
且Φ(x1+ΔxR′,y1)≤T1同时成立,则认为ΔxR′为当前像素点的一个右方向可容忍失真值;采用相同的方法计算当前像素点的右方向水平偏移量集合中的所有右方向可容忍失真值,再从所有右方向可容忍失真值中找出绝对值最大的右方向可容忍失真值,将绝对值最大的右方向可容忍失真值作为当前像素点的右方向最大可容忍失真值,记为ΔR(x1,y1),其中,Ψ(x1+ΔxR′,y1)表示当前像素点和坐标位置为(x1+ΔxR′,y1)的像素点之间的颜色距离,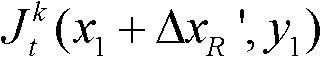 表示
表示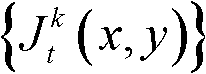 中坐标位置为(x1+ΔxR′,y1)的像素点的最小可察觉变化步长值,Φ(x1+ΔxR′,y1)表示当前像素点和坐标位置为(x1+ΔxR′,y1)的像素点之间的深度距离;
中坐标位置为(x1+ΔxR′,y1)的像素点的最小可察觉变化步长值,Φ(x1+ΔxR′,y1)表示当前像素点和坐标位置为(x1+ΔxR′,y1)的像素点之间的深度距离;
③-5、找出当前像素点的左方向最大可容忍失真值ΔL(x1,y1)和右方向最大可容忍失真值ΔR(x1,y1)中绝对值最小的可容忍失真值,作为当前像素点的最大可容忍失真值,记为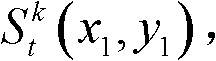 min{}为取最小值函数;
min{}为取最小值函数;
③-6、将t时刻的第k个参考视点的深度图像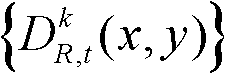 中下一个待处理的像素点作为当前像素点,然后执行步骤③-2至③-6,直至t时刻的第k个参考视点的深度图像
中下一个待处理的像素点作为当前像素点,然后执行步骤③-2至③-6,直至t时刻的第k个参考视点的深度图像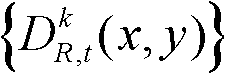 中的所有像素点处理完毕,得到t时刻的第k个参考视点的深度图像
中的所有像素点处理完毕,得到t时刻的第k个参考视点的深度图像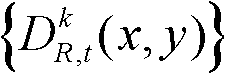 的最大可容忍失真分布图像,记为
的最大可容忍失真分布图像,记为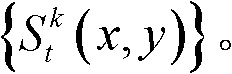
所述的步骤④中置信内容区域和非置信内容区域的分割过程为:
④-1、定义t时刻的第k个参考视点的深度图像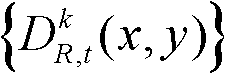 中当前正在处理的像素点为当前像素点;
中当前正在处理的像素点为当前像素点;
④-2、将当前像素点的坐标位置记为p,将当前像素点的邻域像素点的坐标位置记为q,判断当前像素点是否满足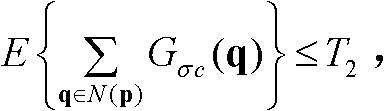 如果是,则确定当前像素点为置信内容,否则,确定当前像素点为非置信内容,其中,E{}为取平均值函数,N(p)表示以坐标位置为p的像素点为中心的7×7邻域窗口,
如果是,则确定当前像素点为置信内容,否则,确定当前像素点为非置信内容,其中,E{}为取平均值函数,N(p)表示以坐标位置为p的像素点为中心的7×7邻域窗口,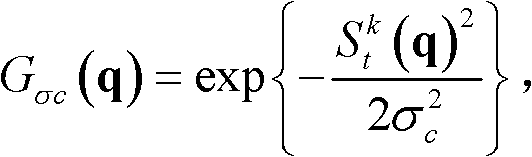 exp{}表示以e为底的指数函数,e=2.71828183,
exp{}表示以e为底的指数函数,e=2.71828183,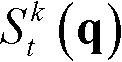 表示坐标位置为p的像素点的最大可容忍失真值,σc表示高斯函数的标准差,0≤T2≤1;
表示坐标位置为p的像素点的最大可容忍失真值,σc表示高斯函数的标准差,0≤T2≤1;
④-3、将t时刻的第k个参考视点的深度图像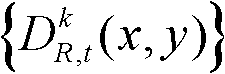 中下一个待处理的像素点作为当前像素点,然后执行步骤④-2至④-3,直至t时刻的第k个参考视点的深度图像
中下一个待处理的像素点作为当前像素点,然后执行步骤④-2至④-3,直至t时刻的第k个参考视点的深度图像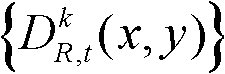 中的所有像素点处理完毕,将所有置信内容构成的区域作为置信内容区域,将所有非置信内容构成的区域作为非置信内容区域。
中的所有像素点处理完毕,将所有置信内容构成的区域作为置信内容区域,将所有非置信内容构成的区域作为非置信内容区域。
所述的步骤⑤的具体过程为:
⑤-1、定义t时刻的第k个参考视点的深度图像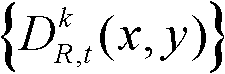 中当前正在处理的像素点为当前像素点;
中当前正在处理的像素点为当前像素点;
⑤-2、将当前像素点的坐标位置记为p,将当前像素点的邻域像素点的坐标位置记为q,定义双向滤波器为其中,Gσs(||p-q||)表示标准差为σs的高斯函数,||p-q||表示坐标位置p和坐标位置q之间的欧氏距离,“||||”为欧氏距离符号,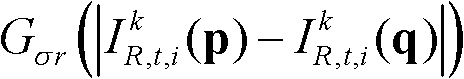 表示标准差为σr的高斯函数,“||”为绝对值符号,
表示标准差为σr的高斯函数,“||”为绝对值符号,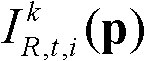 表示t时刻的第k个参考视点的彩色图像
表示t时刻的第k个参考视点的彩色图像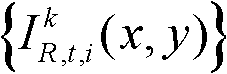 中坐标位置为p的像素点的第i个分量的值,
中坐标位置为p的像素点的第i个分量的值,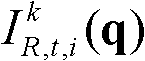 表示t时刻的第k个参考视点的彩色图像
表示t时刻的第k个参考视点的彩色图像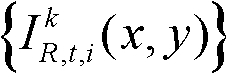 中坐标位置为q的像素点的第i个分量的值,
中坐标位置为q的像素点的第i个分量的值,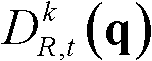 表示t时刻的第k个参考视点的深度图像
表示t时刻的第k个参考视点的深度图像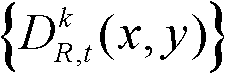 中坐标位置为q的像素点的深度值,exp{}表示以e为底的指数函数,e=2.71828183,N(q)表示以坐标位置为q的像素点为中心的7×7邻域窗口;
中坐标位置为q的像素点的深度值,exp{}表示以e为底的指数函数,e=2.71828183,N(q)表示以坐标位置为q的像素点为中心的7×7邻域窗口;
⑤-3、判断当前像素点是否属于t时刻的第k个参考视点的深度图像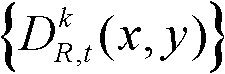 的置信内容区域,如果是,则执行步骤⑤-4,否则,执行步骤⑤-5;
的置信内容区域,如果是,则执行步骤⑤-4,否则,执行步骤⑤-5;
⑤-4、采用标准差为(σs1,σr1)的双向滤波器对当前像素点的坐标位置为q的邻域像素点的深度值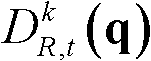 进行滤波操作,得到当前像素点滤波后的深度值,记为
进行滤波操作,得到当前像素点滤波后的深度值,记为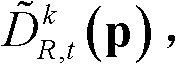 其中,Gσs1(||p-q||)表示标准差为σs1的高斯函数,
其中,Gσs1(||p-q||)表示标准差为σs1的高斯函数,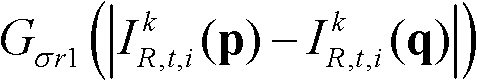 表示标准差为σr1的高斯函数,然后执行步骤⑤-6;
表示标准差为σr1的高斯函数,然后执行步骤⑤-6;
⑤-5、采用标准差为(σs2,σr2)的双向滤波器对当前像素点的坐标位置为q的邻域像素点的深度值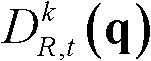 进行滤波操作,得到当前像素点滤波后的深度值,记为
进行滤波操作,得到当前像素点滤波后的深度值,记为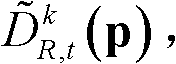 其中,Gσs2(||p-q||)表示标准差为σs2的高斯函数,
其中,Gσs2(||p-q||)表示标准差为σs2的高斯函数,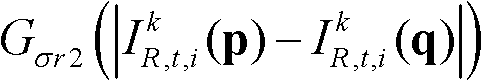 表示标准差为σr2的高斯函数,在此标准差(σs2,σr2)的滤波强度大于标准差(σs1,σr1)的滤波强度;然后执行步骤⑤-6;
表示标准差为σr2的高斯函数,在此标准差(σs2,σr2)的滤波强度大于标准差(σs1,σr1)的滤波强度;然后执行步骤⑤-6;
⑤-6、将t时刻的第k个参考视点的深度图像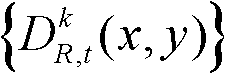 中下一个待处理的像素点作为当前像素点,然后执行步骤⑤-2至⑤-6,直至t时刻的第k个参考视点的深度图像
中下一个待处理的像素点作为当前像素点,然后执行步骤⑤-2至⑤-6,直至t时刻的第k个参考视点的深度图像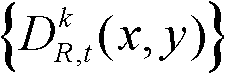 中的所有像素点处理完毕,得到滤波后的深度图像,记为
中的所有像素点处理完毕,得到滤波后的深度图像,记为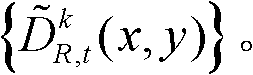
所述的步骤⑤-4中(σs1,σr1)=(5,0.1),所述的步骤⑤-5中(σs2,σr2)=(10,20)。
所述的步骤⑦中设定的编码预测结构为HBP编码预测结构。
与现有技术相比,本发明的优点在于:
1)本发明方法根据不同区域的深度失真对虚拟视点图像绘制的影响以及对3D显示的主观感知质量的影响,将深度图像分成置信内容区域和非置信内容区域,并设计两组不同滤波强度的双向滤波器分别对置信内容区域和非置信内容区域的各个像素点的深度值进行滤波处理,这样保证了虚拟视点图像绘制性能。
2)本发明方法根据人眼的视觉特性得到深度图像的最大可容忍失真分布图像,对最大可容忍失真值较小的区域采用一组强度较小的双向滤波器进行平滑,对最大可容忍失真值较大的区域采用一组强度较高的双向滤波器进行平滑,这样在保证虚拟视点图像绘制性能的基础上,大大提高了深度图像的压缩效率。
附图说明
图1为典型的三维视频系统的基本组成框图;
图2a为“Bookarrival”三维视频测试序列的第9个参考视点的一幅彩色图像;
图2b为“Bookarrival”三维视频测试序列的第11个参考视点的一幅彩色图像;
图2c为图2a所示的彩色图像对应的深度图像;
图2d为图2b所示的彩色图像对应的深度图像;
图3a为“Doorflowers”三维视频测试序列的第8个参考视点的一幅彩色图像;
图3b为“Doorflowers”三维视频测试序列的第10个参考视点的一幅彩色图像;
图3c为图3a所示的彩色图像对应的深度图像;
图3d为图3b所示的彩色图像对应的深度图像;
图4a为“Bookarrival”三维视频测试序列的第9个参考视点的深度图像的最大可容忍失真分布图像;
图4b为“Doorflowers”三维视频测试序列的第8个参考视点的深度图像的最大可容忍失真分布图像;
图5a为“Bookarrival”三维视频测试序列的第9个参考视点的深度图像采用对称高斯滤波处理后的滤波图像;
图5b为“Bookarrival”三维视频测试序列的第9个参考视点的深度图像采用非对称高斯滤波处理后的滤波图像;
图5c为“Bookarrival”三维视频测试序列的第9个参考视点的深度图像采用本发明处理后的滤波图像;
图6a为“Doorflowers”三维视频测试序列的第8个参考视点的深度图像采用对称高斯滤波处理后的滤波图像;
图6b为“Doorflowers”三维视频测试序列的第8个参考视点的深度图像采用非对称高斯滤波处理后的滤波图像;
图6c为“Doorflowers”三维视频测试序列的第8个参考视点的深度图像采用本发明处理后的滤波图像;
图7a为“Bookarrival”三维视频测试序列的第10个参考视点采用原始的深度得到的虚拟视点图像;
图7b为“Bookarrival”三维视频测试序列的第10个参考视点采用对称高斯滤波方法得到的虚拟视点图像;
图7c为“Bookarrival”三维视频测试序列的第10个参考视点采用非对称高斯滤波方法得到的虚拟视点图像;
图7d为“Bookarrival”三维视频测试序列的第10个参考视点采用本发明方法得到的虚拟视点图像;
图8a为“Doorflowers”三维视频测试序列的第9个参考视点采用原始的深度得到的虚拟视点图像;
图8b为“Doorflowers”三维视频测试序列的第9个参考视点采用对称高斯滤波方法得到的虚拟视点图像;
图8c为“Doorflowers”三维视频测试序列的第9个参考视点采用非对称高斯滤波方法得到的虚拟视点图像;
图8d为“Doorflowers”三维视频测试序列的第9个参考视点采用本发明方法得到的虚拟视点图像;
图9a为图7a的局部细节放大图;
图9b为图7b的局部细节放大图;
图9c为图7c的局部细节放大图;
图9d为图7d的局部细节放大图;
图10a为图8a的局部细节放大图;
图10b为图8b的局部细节放大图;
图10c为图8c的局部细节放大图;
图10d为图8d的局部细节放大图。
具体实施方式
以下结合附图实施例对本发明作进一步详细描述。
本发明提出的一种深度图像的预处理方法,其主要包括以下步骤:
①获取t时刻的K个参考视点的K幅颜色空间为YUV的彩色图像及其对应的K幅深度图像,将t时刻的第k个参考视点的彩色图像记为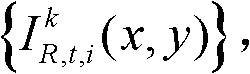 将t时刻的第k个参考视点的深度图像记为
将t时刻的第k个参考视点的深度图像记为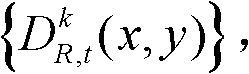 其中,1≤k≤K,k的初始值为1,i=1,2,3分别表示YUV颜色空间的三个分量,YUV颜色空间的第1个分量为亮度分量并记为Y、第2个分量为第一色度分量并记为U及第3个分量为第二色度分量并记为V,(x,y)表示彩色图像或深度图像中像素点的坐标位置,1≤x≤W,1≤y≤H,W表示彩色图像或深度图像的宽度,H表示彩色图像或深度图像的高度,
其中,1≤k≤K,k的初始值为1,i=1,2,3分别表示YUV颜色空间的三个分量,YUV颜色空间的第1个分量为亮度分量并记为Y、第2个分量为第一色度分量并记为U及第3个分量为第二色度分量并记为V,(x,y)表示彩色图像或深度图像中像素点的坐标位置,1≤x≤W,1≤y≤H,W表示彩色图像或深度图像的宽度,H表示彩色图像或深度图像的高度, 表示t时刻的第k个参考视点的彩色图像
表示t时刻的第k个参考视点的彩色图像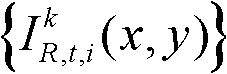 中坐标位置为(x,y)的像素点的第i个分量的值,
中坐标位置为(x,y)的像素点的第i个分量的值,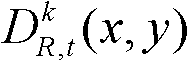 表示t时刻的第k个参考视点的深度图像
表示t时刻的第k个参考视点的深度图像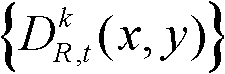 中坐标位置为(x,y)的像素点的深度值。
中坐标位置为(x,y)的像素点的深度值。
在此,采用德国HHI实验室提供的三维视频测试序列“Bookarrival”和“Doorflowerss”,这两个三维视频测试序列均包括16个参考视点的16幅彩色图像和对应的16幅深度图像,各幅彩色图像和深度图像的分辨率都为1024×768,帧率为15帧每秒,即15fps,这两个三维视频测试序列是ISO/MPEG所推荐的标准测试序列。图2a和图2b分别给出了“Bookarrival”的第9个和第11个参考视点的一幅彩色图像;图2c和图2d分别给出了“Bookarrival”的第9个和第11个参考视点的彩色图像所对应的深度图像;图3a和图3b分别给出了“Doorflowers”的第8个和第10个参考视点的一幅彩色图像;图3c和图3d分别给出了“Doorflowers”的第8个和第10个参考视点的彩色图像所对应的深度图像。
②人类视觉系统(HVS)特性表明,人眼对图像中变化较小的属性或噪声是不可感知的,除非该属性或噪声的变化强度超过某一阈值,该阈值就是最小可察觉变化步长(JustNoticeable Difference,JND)。而人眼的视觉掩蔽效应是一种局部效应,受背景照度、纹理复杂度等因素的影响,背景越亮,纹理越复杂,界限值就越高。因此本发明利用人类视觉对背景光照和纹理的视觉掩蔽效应,提取出t时刻的第k个参考视点的彩色图像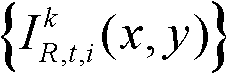 的最小可察觉变化步长图像,记为
的最小可察觉变化步长图像,记为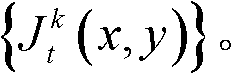
在此具体实施例中,t时刻的第k个参考视点的彩色图像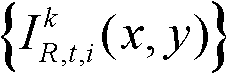 的最小可察觉变化步长图像
的最小可察觉变化步长图像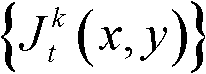 的提取过程为:
的提取过程为:
②-1、计算t时刻的第k个参考视点的彩色图像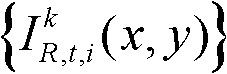 的背景光照的视觉掩蔽效应的可视化阈值集合,记为{Tl(x,y)},
的背景光照的视觉掩蔽效应的可视化阈值集合,记为{Tl(x,y)},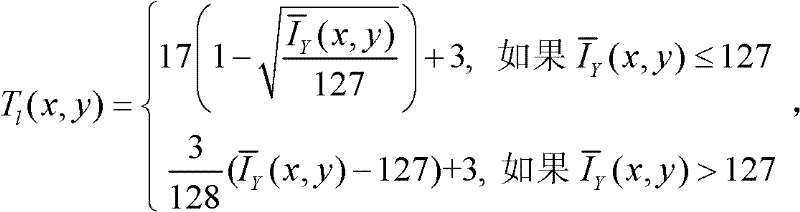 其中,
其中,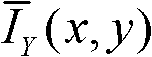 表示t时刻的第k个参考视点的彩色图像
表示t时刻的第k个参考视点的彩色图像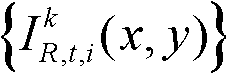 中以坐标位置为(x,y)的像素点为中心的5×5窗口内的所有像素点的亮度平均值,在实际处理过程中,也可以采用其它大小的窗口,但经大量实验,结果表明采用5×5大小的窗口时可以取得最好的效果。
中以坐标位置为(x,y)的像素点为中心的5×5窗口内的所有像素点的亮度平均值,在实际处理过程中,也可以采用其它大小的窗口,但经大量实验,结果表明采用5×5大小的窗口时可以取得最好的效果。
②-2、计算t时刻的第k个参考视点的彩色图像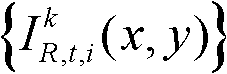 的纹理的视觉掩蔽效应的可视化阈值集合,记为{Tt(x,y)},Tt(x,y)=η×G(x,y)×We(x,y),其中,η为大于0的控制因子,在本实施例中,η=0.05,G(x,y)表示对t时刻的第k个参考视点的彩色图像
的纹理的视觉掩蔽效应的可视化阈值集合,记为{Tt(x,y)},Tt(x,y)=η×G(x,y)×We(x,y),其中,η为大于0的控制因子,在本实施例中,η=0.05,G(x,y)表示对t时刻的第k个参考视点的彩色图像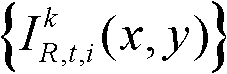 中坐标位置为(x,y)的像素点进行定向高通滤波得到的最大加权平均值,We(x,y)表示对t时刻的第k个参考视点的彩色图像
中坐标位置为(x,y)的像素点进行定向高通滤波得到的最大加权平均值,We(x,y)表示对t时刻的第k个参考视点的彩色图像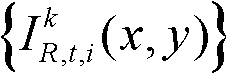 的边缘图像中坐标位置为(x,y)的像素点进行高斯低通滤波得到的边缘加权值。
的边缘图像中坐标位置为(x,y)的像素点进行高斯低通滤波得到的边缘加权值。
②-3、对t时刻的第k个参考视点的彩色图像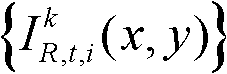 的背景光照的视觉掩蔽效应的可视化阈值集合{Tl(x,y)}和纹理的视觉掩蔽效应的可视化阈值集合{Tt(x,y)}进行融合,得到t时刻的第k个参考视点的彩色图像
的背景光照的视觉掩蔽效应的可视化阈值集合{Tl(x,y)}和纹理的视觉掩蔽效应的可视化阈值集合{Tt(x,y)}进行融合,得到t时刻的第k个参考视点的彩色图像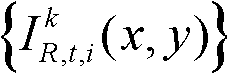 的最小可察觉变化步长图像,记为
的最小可察觉变化步长图像,记为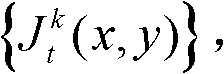 其中,Cl,t表示控制背景光照和纹理的视觉掩蔽效应重叠影响的参数,0<Cl,t<1,在本实施例中,Cl,t=0.5,min{}为取最小值函数。
其中,Cl,t表示控制背景光照和纹理的视觉掩蔽效应重叠影响的参数,0<Cl,t<1,在本实施例中,Cl,t=0.5,min{}为取最小值函数。
③由于深度图像的失真,通过基于深度图像的绘制得到的绘制图像与真实图像之间会存在几何失真(也称为结构位置失真),并且深度失真与几何失真之间近似成线性映射关系,因此,绘制图像的几何失真大小可以直接通过测量深度图像的失真大小来反映。
本发明根据t时刻的第k个参考视点的彩色图像的最小可察觉变化步长图像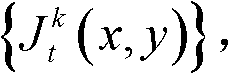 提取出t时刻的第k个参考视点的深度图像
提取出t时刻的第k个参考视点的深度图像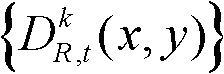 的最大可容忍失真分布图像,记为
的最大可容忍失真分布图像,记为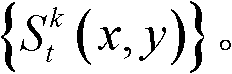
在此具体实施例中,t时刻的第k个参考视点的深度图像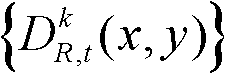 的最大可容忍失真分布图像
的最大可容忍失真分布图像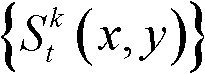 的提取过程为:
的提取过程为:
③-1、定义t时刻的第k个参考视点的深度图像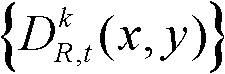 中当前正在处理的像素点为当前像素点。
中当前正在处理的像素点为当前像素点。
③-2、将当前像素点的坐标位置记为(x1,y1),将与当前像素点水平相邻的像素点的坐标位置记为(x1+Δx,y1),计算当前像素点和与其水平相邻的像素点之间的颜色距离,记为Ψ(x1+Δx,y1),计算当前像素点和与其水平相邻的像素点之间的深度距离,记为Φ(x1+Δx,y1),其中,Δx表示水平偏移量,-W′≤Δx<0或0<Δx≤W′,W′为最大水平偏移量,在本实施例中,W′=15,“||”为绝对值符号,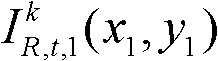 表示t时刻的第k个参考视点的彩色图像
表示t时刻的第k个参考视点的彩色图像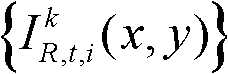 中坐标位置为(x1,y1)的像素点的Y分量的值,
中坐标位置为(x1,y1)的像素点的Y分量的值,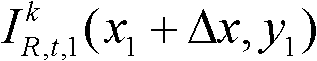 表示t时刻的第k个参考视点的彩色图像
表示t时刻的第k个参考视点的彩色图像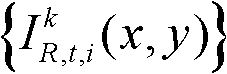 中坐标位置为(x1+Δx,y1)的像素点的Y分量的值,
中坐标位置为(x1+Δx,y1)的像素点的Y分量的值,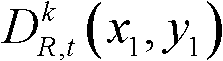 表示t时刻的第k个参考视点的深度图像
表示t时刻的第k个参考视点的深度图像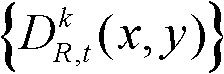 中坐标位置为(x1,y1)的像素点的深度值,
中坐标位置为(x1,y1)的像素点的深度值,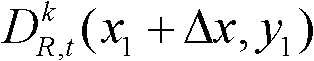 表示t时刻的第k个参考视点的深度图像
表示t时刻的第k个参考视点的深度图像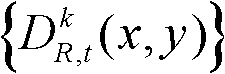 中坐标位置为(x1+Δx,y1)的像素点的深度值。
中坐标位置为(x1+Δx,y1)的像素点的深度值。
③-3、从当前像素点的左方向水平偏移量集合{ΔxL|-W′≤ΔxL≤-1}中任取一个ΔxL′,如果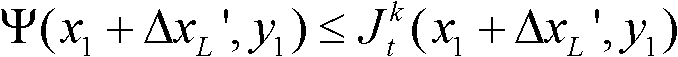 且Φ(x1+ΔxL′,y1)≤T1同时成立,则认为ΔxL′为当前像素点的一个左方向可容忍失真值;采用相同的方法计算当前像素点的左方向水平偏移量集合中的所有左方向可容忍失真值,再从所有左方向可容忍失真值中找出绝对值最大的左方向可容忍失真值,将绝对值最大的左方向可容忍失真值作为当前像素点的左方向最大可容忍失真值,记为ΔL(x1,y1),其中,Ψ(x1+ΔxL′,y1)表示当前像素点和坐标位置为(x1+ΔxL′,y1)的像素点之间的颜色距离,
且Φ(x1+ΔxL′,y1)≤T1同时成立,则认为ΔxL′为当前像素点的一个左方向可容忍失真值;采用相同的方法计算当前像素点的左方向水平偏移量集合中的所有左方向可容忍失真值,再从所有左方向可容忍失真值中找出绝对值最大的左方向可容忍失真值,将绝对值最大的左方向可容忍失真值作为当前像素点的左方向最大可容忍失真值,记为ΔL(x1,y1),其中,Ψ(x1+ΔxL′,y1)表示当前像素点和坐标位置为(x1+ΔxL′,y1)的像素点之间的颜色距离,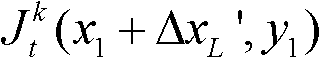 表示
表示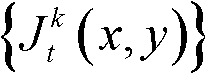 中坐标位置为(x1+ΔxL′,y1)的像素点的最小可察觉变化步长值,Φ(x1+ΔxL′,y1)表示当前像素点和坐标位置为(x1+ΔxL′,y1)的像素点之间的深度距离,T1为深度敏感性阈值,在本实施例中,T1的取值与t时刻的第k个参考视点的深度图像
中坐标位置为(x1+ΔxL′,y1)的像素点的最小可察觉变化步长值,Φ(x1+ΔxL′,y1)表示当前像素点和坐标位置为(x1+ΔxL′,y1)的像素点之间的深度距离,T1为深度敏感性阈值,在本实施例中,T1的取值与t时刻的第k个参考视点的深度图像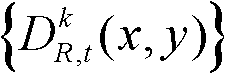 中坐标位置为(x1,y1)的像素点的深度值
中坐标位置为(x1,y1)的像素点的深度值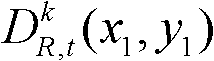 有关,如果
有关,如果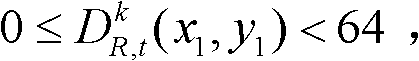 则取T1=21,如果
则取T1=21,如果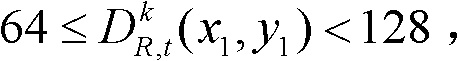 则取T1=19,如果
则取T1=19,如果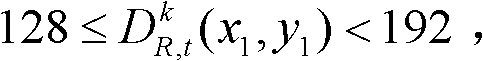 则取T1=18,如果则取T1=20。
则取T1=18,如果则取T1=20。
③-4、从当前像素点的右方向水平偏移量集合{ΔxR|1≤ΔxR≤W′}中任取一个ΔxR′,如果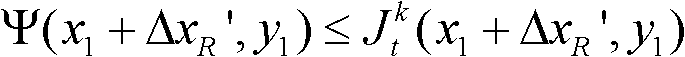 且Φ(x1+ΔxR′,y1)≤T1同时成立,则认为ΔxR′为当前像素点的一个右方向可容忍失真值;采用相同的方法计算当前像素点的右方向水平偏移量集合中的所有右方向可容忍失真值,再从所有右方向可容忍失真值中找出绝对值最大的右方向可容忍失真值,将绝对值最大的右方向可容忍失真值作为当前像素点的右方向最大可容忍失真值,记为ΔR(x1,y1),其中,Ψ(x1+ΔxR′,y1)表示当前像素点和坐标位置为(x1+ΔxR′,y1)的像素点之间的颜色距离,
且Φ(x1+ΔxR′,y1)≤T1同时成立,则认为ΔxR′为当前像素点的一个右方向可容忍失真值;采用相同的方法计算当前像素点的右方向水平偏移量集合中的所有右方向可容忍失真值,再从所有右方向可容忍失真值中找出绝对值最大的右方向可容忍失真值,将绝对值最大的右方向可容忍失真值作为当前像素点的右方向最大可容忍失真值,记为ΔR(x1,y1),其中,Ψ(x1+ΔxR′,y1)表示当前像素点和坐标位置为(x1+ΔxR′,y1)的像素点之间的颜色距离,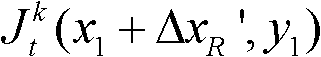 表示
表示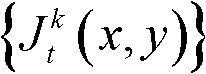 中坐标位置为(x1+ΔxR′,y1)的像素点的最小可察觉变化步长值,Φ(x1+ΔxR′,y1)表示当前像素点和坐标位置为(x1+ΔxR′,y1)的像素点之间的深度距离。
中坐标位置为(x1+ΔxR′,y1)的像素点的最小可察觉变化步长值,Φ(x1+ΔxR′,y1)表示当前像素点和坐标位置为(x1+ΔxR′,y1)的像素点之间的深度距离。
③-5、找出当前像素点的左方向最大可容忍失真值ΔL(x1,y1)和右方向最大可容忍失真值ΔR(x1,y1)中绝对值最小的可容忍失真值,作为当前像素点的最大可容忍失真值,记为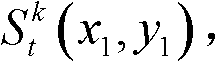 min{}为取最小值函数。
min{}为取最小值函数。
③-6、将t时刻的第k个参考视点的深度图像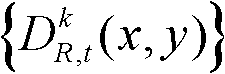 中下一个待处理的像素点作为当前像素点,然后执行步骤③-2至③-6,直至t时刻的第k个参考视点的深度图像
中下一个待处理的像素点作为当前像素点,然后执行步骤③-2至③-6,直至t时刻的第k个参考视点的深度图像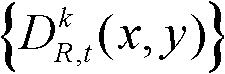 中的所有像素点处理完毕,得到t时刻的第k个参考视点的深度图像
中的所有像素点处理完毕,得到t时刻的第k个参考视点的深度图像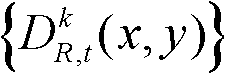 的最大可容忍失真分布图像,记为
的最大可容忍失真分布图像,记为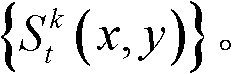
在本实施例中,图4a给出了“Bookarrival”的第9个参考视点的深度图像的最大可容忍失真分布图像,图4b给出了“Doorflowers”的第8个参考视点的深度图像的最大可容忍失真分布图像,在深度图像的最大可容忍失真分布图像中,如果像素点的像素值越大,则表示该像素点可容忍的失真也就越小,从图4a和图4b可以看出,采用本发明得到的最大可容忍失真分布图像,能够准确地反映不同区域的失真对绘制的影响程度。
④根据t时刻的第k个参考视点的深度图像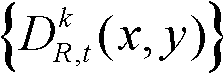 的最大可容忍失真分布图像
的最大可容忍失真分布图像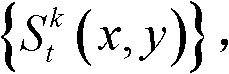 将t时刻的第k个参考视点的深度图像
将t时刻的第k个参考视点的深度图像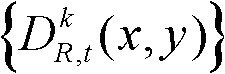 分割成置信内容区域和非置信内容区域。
分割成置信内容区域和非置信内容区域。
在此具体实施例中,置信内容区域和非置信内容区域的分割过程为:
④-1、定义t时刻的第k个参考视点的深度图像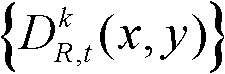 中当前正在处理的像素点为当前像素点。
中当前正在处理的像素点为当前像素点。
④-2、将当前像素点的坐标位置记为p,将当前像素点的邻域像素点的坐标位置记为q,判断当前像素点是否满足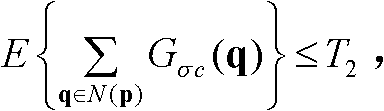 如果是,则确定当前像素点为置信内容,否则,确定当前像素点为非置信内容,其中,E{}为取平均值函数,N(p)表示以坐标位置为p的像素点为中心的7×7邻域窗口,在实际处理过程中,也可采用其它大小的邻域窗口,但经大量实验,表明采用7×7邻域窗口时能够达到最好的效果,
如果是,则确定当前像素点为置信内容,否则,确定当前像素点为非置信内容,其中,E{}为取平均值函数,N(p)表示以坐标位置为p的像素点为中心的7×7邻域窗口,在实际处理过程中,也可采用其它大小的邻域窗口,但经大量实验,表明采用7×7邻域窗口时能够达到最好的效果,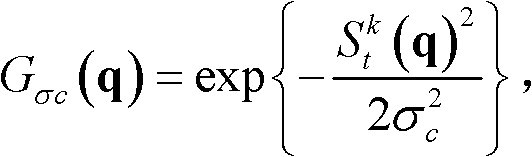 exp{}表示以e为底的指数函数,e=2.71828183,
exp{}表示以e为底的指数函数,e=2.71828183,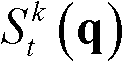 表示坐标位置为p的像素点的最大可容忍失真值,σc表示高斯函数的标准差,0≤T2≤1,在本实施例中,σc=5,T2=0.4。
表示坐标位置为p的像素点的最大可容忍失真值,σc表示高斯函数的标准差,0≤T2≤1,在本实施例中,σc=5,T2=0.4。
④-3、将t时刻的第k个参考视点的深度图像 中下一个待处理的像素点作为当前像素点,然后执行步骤④-2至④-3,直至t时刻的第k个参考视点的深度图像
中下一个待处理的像素点作为当前像素点,然后执行步骤④-2至④-3,直至t时刻的第k个参考视点的深度图像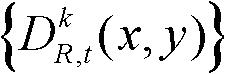 中的所有像素点处理完毕,将所有置信内容构成的区域作为置信内容区域,将所有非置信内容构成的区域作为非置信内容区域。
中的所有像素点处理完毕,将所有置信内容构成的区域作为置信内容区域,将所有非置信内容构成的区域作为非置信内容区域。
⑤利用两组不同滤波强度的双向滤波器分别对t时刻的第k个参考视点的深度图像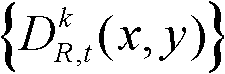 的置信内容区域和非置信内容区域中的各个像素点对应的深度值进行滤波处理,得到滤波后的深度图像,记为
的置信内容区域和非置信内容区域中的各个像素点对应的深度值进行滤波处理,得到滤波后的深度图像,记为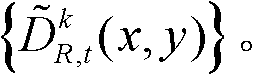
由于深度图像整体非常平滑,对深度图像进行滤波处理,要求在平滑深度信息的同时能很好地保留边缘轮廓信息,双向滤波器(bilateral filter)是一种非线性滤波器,能有效地将噪声平滑化且又可以把重要的边界保留,其主要原理是同时在空间域(spatialdomain)和强度域(intensity domain)做高斯平滑化(Gaussian smoothing)处理。由于深度图像与彩色图像之间存在较强的相关性,深度图像与彩色图像的运动对象及运动对象边界是一致的,但彩色图像包含更加丰富的纹理信息,以彩色图像作为强度域信息来辅助深度图像的滤波,有利于保留重要的运动对象边界信息。通过分析,本发明提出的滤波处理的具体过程为:
⑤-1、定义t时刻的第k个参考视点的深度图像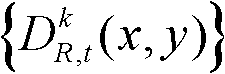 中当前正在处理的像素点为当前像素点。
中当前正在处理的像素点为当前像素点。
⑤-2、将当前像素点的坐标位置记为p,将当前像素点的邻域像素点的坐标位置记为q,定义双向滤波器为其中,Gσs(||p-q||)表示标准差为σs的高斯函数,||p-q||表示坐标位置p和坐标位置q之间的欧氏距离,“||||”为欧氏距离符号,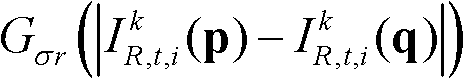 表示标准差为σr的高斯函数,“||”为绝对值符号,
表示标准差为σr的高斯函数,“||”为绝对值符号,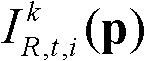 表示t时刻的第k个参考视点的彩色图像
表示t时刻的第k个参考视点的彩色图像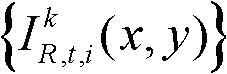 中坐标位置为p的像素点的第i个分量的值,
中坐标位置为p的像素点的第i个分量的值,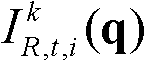 表示t时刻的第k个参考视点的彩色图像
表示t时刻的第k个参考视点的彩色图像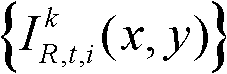 中坐标位置为q的像素点的第i个分量的值,
中坐标位置为q的像素点的第i个分量的值,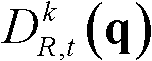 表示t时刻的第k个参考视点的深度图像
表示t时刻的第k个参考视点的深度图像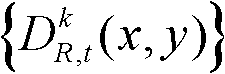 中坐标位置为q的像素点的深度值,exp{}表示以e为底的指数函数,e=2.71828183,N(q)表示以坐标位置为q的像素点为中心的7×7邻域窗口。
中坐标位置为q的像素点的深度值,exp{}表示以e为底的指数函数,e=2.71828183,N(q)表示以坐标位置为q的像素点为中心的7×7邻域窗口。
⑤-3、判断当前像素点是否属于t时刻的第k个参考视点的深度图像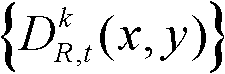 的置信内容区域,如果是,则执行步骤⑤-4,否则,执行步骤⑤-5。
的置信内容区域,如果是,则执行步骤⑤-4,否则,执行步骤⑤-5。
⑤-4、采用标准差为(σs1,σr1)的双向滤波器对当前像素点的坐标位置为q的邻域像素点的深度值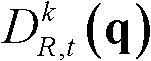 进行滤波操作,得到当前像素点滤波后的深度值,记为
进行滤波操作,得到当前像素点滤波后的深度值,记为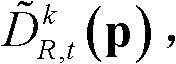 其中,Gσs1(||p-q||)表示标准差为σs1的高斯函数,
其中,Gσs1(||p-q||)表示标准差为σs1的高斯函数,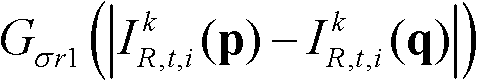 表示标准差为σr1的高斯函数,然后执行步骤⑤-6。
表示标准差为σr1的高斯函数,然后执行步骤⑤-6。
在此,标准差(σs1,σr1)采用一组滤波强度较小的标准差,如(σs1,σr1)的大小可为(5,0.1)。
⑤-5、采用标准差为(σs2,σr2)的双向滤波器对当前像素点的坐标位置为q的邻域像素点的深度值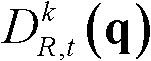 进行滤波操作,得到当前像素点滤波后的深度值,记为
进行滤波操作,得到当前像素点滤波后的深度值,记为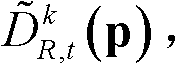 其中,Gσs2(||p-q||)表示标准差为σs2的高斯函数,
其中,Gσs2(||p-q||)表示标准差为σs2的高斯函数,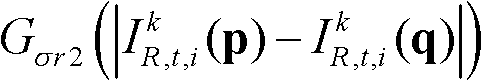 表示标准差为σr2的高斯函数,在此标准差(σs2,σr2)的滤波强度大于标准差(σs1,σr1)的滤波强度;然后执行步骤⑤-6。
表示标准差为σr2的高斯函数,在此标准差(σs2,σr2)的滤波强度大于标准差(σs1,σr1)的滤波强度;然后执行步骤⑤-6。
在此,标准差(σs2,σr2)采用一组滤波强度较大的标准差,如(σs2,μr2)的大小可为(10,20)。
⑤-6、将t时刻的第k个参考视点的深度图像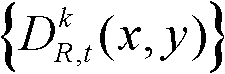 中下一个待处理的像素点作为当前像素点,然后执行步骤⑤-2至⑤-6,直至t时刻的第k个参考视点的深度图像
中下一个待处理的像素点作为当前像素点,然后执行步骤⑤-2至⑤-6,直至t时刻的第k个参考视点的深度图像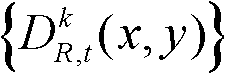 中的所有像素点处理完毕,得到滤波后的深度图像,记为
中的所有像素点处理完毕,得到滤波后的深度图像,记为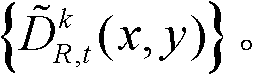
对“Bookarrival”和“Doorflowers”三维视频测试序列的深度图像进行滤波处理实验,图5a和图5b分别给出了“Bookarrival”的第9个参考视点的深度图像分别采用现有的对称高斯滤波方法和非对称高斯滤波方法处理后的深度图像,图5c给出了“Bookarrival”的第9个参考视点的深度图像经本发明滤波处理后的深度图像;图6a和图6b分别给出了“Doorflowers”的第8个参考视点的深度图像分别采用现有的对称高斯滤波方法和非对称高斯滤波方法处理后的深度图像,图6c给出了“Doorflowers”的第8个参考视点的深度图像经本发明滤波处理后的深度图像,从图5c和图6c可以看出,采用本发明得到滤波处理后的深度图像,保持了深度图像的重要的几何特征,产生了令人满意的锐利的边缘和平滑的轮廓。
⑥令k′=k+1,k=k′,返回步骤②继续执行,直至得到t时刻的K个参考视点的K幅滤波后的深度图像,K幅滤波后的深度图像用集合表示为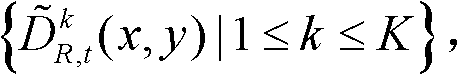 其中,k′的初始值为0;
其中,k′的初始值为0;
⑦根据设定的编码预测结构分别对t时刻的K个参考视点的K幅颜色空间为YUV的彩色图像及其对应的K幅滤波后的深度图像进行编码,再将编码后的K幅彩色图像及其对应的K幅深度图像经网络传输给解码端;
在本实施中,设定的编码预测结构采用公知的HBP编码预测结构。
⑧在解码端对编码后的K幅彩色图像及其对应的K幅深度图像进行解码,获得解码后的t时刻的K个参考视点的K幅彩色图像及其对应的K幅深度图像,采用基于深度图像的绘制得到虚拟视点图像。
以下就利用本发明方法对“Bookarrival”和“Doorflowers”三维视频测试序列进行虚拟视点图像绘制的主观和客观性能进行比较。
将采用本发明方法得到的虚拟视点图像,与不采用本发明方法得到的虚拟视点图像进行比较。图7a给出了“Bookarrival”三维视频测试序列的第10个参考视点采用原始的深度得到的虚拟视点图像,图7b给出了“Bookarrival”的第10个参考视点采用现有的对称高斯滤波方法得到的虚拟视点图像,图7c给出了“Bookarrival”的第10个参考视点采用现有的非对称高斯滤波方法得到的虚拟视点图像,图7d给出了“Bookarrival”的第10个参考视点采用本发明方法得到的虚拟视点图像;图8a给出了“Doorflowers”三维视频测试序列的第9个参考视点采用原始的深度得到的虚拟视点图像,图8b给出了“Doorflowers”的第9个参考视点采用现有的对称高斯滤波方法得到的虚拟视点图像,图8c给出了“Doorflowers”的第9个参考视点采用现有的非对称高斯滤波方法得到的虚拟视点图像,图8d给出了“Doorflowers”的第9个参考视点采用本发明方法得到的虚拟视点图像;图9a、图9b、图9c和图9d分别给出了图7a、图7b、图7c和图7d的局部细节放大图;图10a、图10b、图10c和图10d分别给出了图8a、图8b、图8c和图8d的局部细节放大图。从图7a至图10d可以看出,采用本发明方法得到的虚拟视点图像能够保持更好的对象轮廓信息,从而降低了由于深度图像的失真引起的映射过程中产生的背景对前景的覆盖,并且对背景区域进行强度较大的滤波平滑处理,能够有效地消除绘制的虚拟视点图像中的条纹噪声。
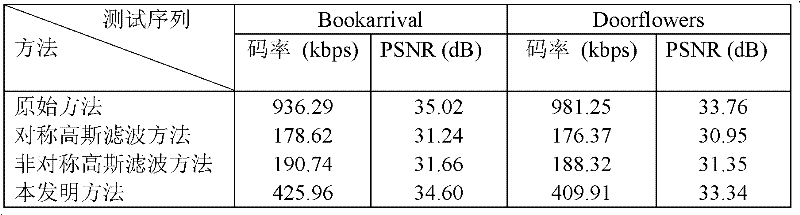
将采用本发明方法的编码性能,与其他方法的编码性能进行比较,比较结果如表1所示。四种方法均采用JMVM 4.0平台,量化步长QP=22,帧组的尺寸为15,也即时域上需要编码的帧数为15,每个视点总的编码帧数为60帧,编码2个视点。对“Bookarrival”和“Doorflowers”采用对称高斯滤波和非对称高斯滤波处理后,能够大大节省编码的码率,但绘制性能也下降2~3dB以上,而采用本发明方法处理后,码率节省能够达到50%以上并且绘制性能下降在0.4dB范围内,说明本发明方法是有效可行的。
表1采用本发明与其他方法的编码和绘制性能比较