
技术领域
本发明涉及一种视频信号的处理方法,尤其是涉及一种视频显著图提取方法。
背景技术
在人类视觉接收与信息处理中,由于大脑资源有限以及外界环境信息重要性区别,因此在处理过程中人脑对外界环境信息并不是一视同仁的,而是表现出选择特征。人们在观看图像或者视频片段时注意力并非均匀分布到图像的每个区域,而是对某些显著区域关注度更高。如何将视频中视觉注意度高的显著区域检测并提取出来是计算机视觉以及基于内容的视频检索领域的一个重要的研究内容。
目前,通常采用视频分割、光流法、运动估计等方法来提取视频显著区域,然而这些方法并不能很好地将运动的物体和静态背景进行分离,这是因为:一方面,通过运动估计或帧差法得到的运动信息只反映运动趋势,并不能很好地反映运动显著语义特征;另一方面,视频中的静态场景也会影响视觉注意力的判断,在某些情况下,空间显著图会起主要的作用,因此,如何提取反映运动显著语义特征的运动显著图,如何对运动显著图和空间显著图进行结合,都是视频显著图提取中需要研究解决的问题。
发明内容
本发明所要解决的技术问题是提供一种符合人眼运动显著语义特征,且提取精度高的视频显著图提取方法。
本发明解决上述技术问题所采用的技术方案为:一种视频显著图提取方法,其特征在于包括以下步骤:
①对呈三维立方体的二维视频在时域上进行采样,得到二维视频的T个X-Y截面图像,即得到二维视频的T个时刻的视频帧,将二维视频中的t时刻的视频帧记为{It(x,y)},将{It(x,y)}中坐标位置为(x,y)的像素点的像素值记为It(x,y),其中,T表示二维视频中包含的视频帧的总帧数,1≤t≤T,1≤x≤W,1≤y≤H,W表示二维视频中各时刻的视频帧的宽,H表示二维视频中各时刻的视频帧的高;
同样,对呈三维立方体的二维视频在X方向上进行采样,得到二维视频的W个Y-T截面图像,将二维视频中的第x个Y-T截面图像记为{Ix(y,t)},将{Ix(y,t)}中坐标位置为(y,t)的像素点的像素值记为Ix(y,t),Ix(y,t)=It(x,y);
同样,对呈三维立方体的二维视频在Y方向上进行采样,得到二维视频的H个X-T截面图像,将二维视频中的第y个X-T截面图像记为{Iy(x,t)},将{Iy(x,t)}中坐标位置为(x,t)的像素点的像素值记为Iy(x,t),Iy(x,t)=It(x,y);
②对二维视频中的每个Y-T截面图像进行低秩矩阵分解,并获取二维视频中的每个Y-T截面图像的最优垂直方向运动矩阵,同样对二维视频中的每个X-T截面图像进行低秩矩阵分解,并获取二维视频中的每个X-T截面图像的最优水平方向运动矩阵;然后根据二维视频中的每个Y-T截面图像的最优垂直方向运动矩阵和每个X-T截面图像的最优水平方向运动矩阵,获取二维视频中每个时刻的视频帧的运动显著图,将二维视频中的t时刻的视频帧{It(x,y)}的运动显著图记为{St,motion(x,y)},其中,St,motion(x,y)表示{St,motion(x,y)}中坐标位置为(x,y)的像素点的像素值;
③提取二维视频中每个时刻的视频帧中的每个像素点的特征矢量;然后对提取得到的所有像素点的特征矢量构成的矩阵进行低秩矩阵分解,并获取二维视频中每个时刻的视频帧中的所有像素点的特征矢量构成的矩阵的最优背景矩阵和最优运动矩阵;再根据二维视频中每个时刻的视频帧中的所有像素点的特征矢量构成的矩阵的最优运动矩阵,获得二维视频中每个时刻的视频帧的空间显著图,将二维视频中的t时刻的视频帧{It(x,y)}的空间显著图记为{St,spatial(x,y)},其中,St,spatial(x,y)表示{St,spatial(x,y)}中坐标位置为(x,y)的像素点的像素值;
④对二维视频中每个时刻的视频帧的运动显著图和空间显著图进行融合,得到二维视频中每个时刻的视频帧的视频显著图,将二维视频中t时刻的视频帧{It(x,y)}的视频显著图记为{Svideo(x,y)},将{Svideo(x,y)}中坐标位置为(x,y)的像素点的像素值记为Svideo(x,y),Svideo(x,y)=(St,motion(x,y))α×(St,spatial(x,y))1-α,其中,α为权重系数。
所述的步骤②的具体过程为:
②-1、对二维视频中的每个Y-T截面图像进行低秩矩阵分解,得到二维视频中的每个Y-T截面图像的所有垂直方向背景矩阵和所有垂直方向运动矩阵;
②-2、利用最小化概率密度函数,获取二维视频中的每个Y-T截面图像的最优垂直方向背景矩阵和最优垂直方向运动矩阵,将二维视频中的第x个Y-T截面图像{Ix(y,t)}的最优垂直方向背景矩阵和最优垂直方向运动矩阵对应记为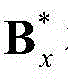 和
和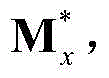 将
将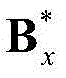 和
和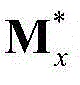 的组合记为
的组合记为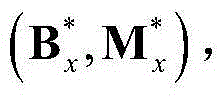 其中,Sx为二维视频中的第x个Y-T截面图像{Ix(y,t)}的矩阵形式表示,
其中,Sx为二维视频中的第x个Y-T截面图像{Ix(y,t)}的矩阵形式表示,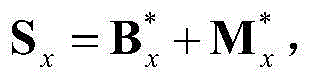 Sx、
Sx、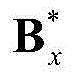 和
和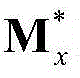 的维数均为H×T,argmin[]表示最小化概率密度函数,Ωx表示对Sx进行低秩矩阵分解得到的所有的垂直方向背景矩阵和垂直方向运动矩阵的组合(Bx,Mx)的集合,(Bx,Mx)∈Ωx,符号“|| ||*”为求取矩阵核的范数符号,符号“|| ||1”为求取矩阵的1-范数符号,λ为拉格朗日乘子;
的维数均为H×T,argmin[]表示最小化概率密度函数,Ωx表示对Sx进行低秩矩阵分解得到的所有的垂直方向背景矩阵和垂直方向运动矩阵的组合(Bx,Mx)的集合,(Bx,Mx)∈Ωx,符号“|| ||*”为求取矩阵核的范数符号,符号“|| ||1”为求取矩阵的1-范数符号,λ为拉格朗日乘子;
②-3、根据二维视频的W个Y-T截面图像各自的最优垂直方向运动矩阵,通过在X方向上进行叠加,构造得到Y-T截面图像的立方体,记为ScubeYT,其中,ScubeYT的维数为W×H×T;
②-4、对二维视频中的每个X-T截面图像进行低秩矩阵分解,得到二维视频中的每个X-T截面图像的所有水平方向背景矩阵和所有水平方向运动矩阵;
②-5、利用最小化概率密度函数,获取二维视频中的每个X-T截面图像的最优水平方向背景矩阵和最优水平方向运动矩阵,将二维视频中的第y个X-T截面图像{Iy(x,t)}的最优水平方向背景矩阵和最优水平方向运动矩阵对应记为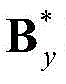 和
和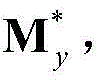 将
将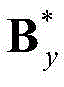 和
和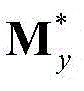 的组合记为
的组合记为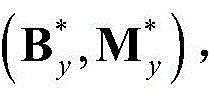 其中,Sy为二维视频中的第y个X-T截面图像{Iy(x,t)}的矩阵形式表示,
其中,Sy为二维视频中的第y个X-T截面图像{Iy(x,t)}的矩阵形式表示,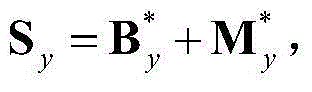 Sy、
Sy、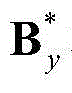 和
和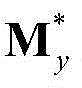 的维数均为W×T,Ωy表示对Sy进行低秩矩阵分解得到的所有的水平方向背景矩阵和水平方向运动矩阵的组合(By,My)的集合,(By,My)∈Ωy;
的维数均为W×T,Ωy表示对Sy进行低秩矩阵分解得到的所有的水平方向背景矩阵和水平方向运动矩阵的组合(By,My)的集合,(By,My)∈Ωy;
②-6、根据二维视频的H个X-T截面图像各自的最优水平方向运动矩阵,通过在Y方向上进行叠加,构造得到X-T截面图像的立方体,记为ScubeXT,其中,ScubeXT的维数为W×H×T;
②-7、计算norm(ScubeXT·*ScubeYT)作为二维视频的初步的运动显著图,其中,norm()表示归一化操作,norm(ScubeXT·*ScubeYT)中的符号“·*”为矩阵点乘符号;
②-8、采用高斯滤波器对二维视频的初步的运动显著图中每个时刻的X-Y截面图像进行平滑操作,得到二维视频中每个时刻的视频帧的运动显著图,将二维视频中的t时刻的视频帧{It(x,y)}的运动显著图记为{St,motion(x,y)},将{St,motion(x,y)}中坐标位置为(x,y)的像素点的像素值记为St,motion(x,y),St,motion(x,y)=S′t,motion(x,y)*Gσ(x,y),其中,S′t,motion(x,y)表示二维视频的初步的运动显著图中的t时刻的X-Y截面图像,“*”为卷积操作符号,Gσ(x,y)表示标准差为σ的高斯函数,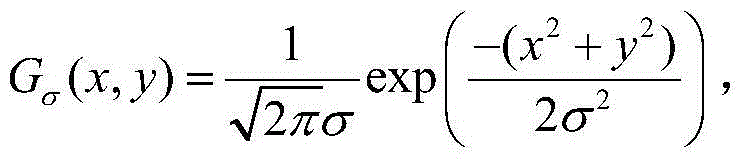 exp()为以e为底的指数函数,e表示自然基数。
exp()为以e为底的指数函数,e表示自然基数。
所述的步骤②-2和所述的步骤②-5中取λ=0.06;所述的步骤②-8中取σ=5。
所述的步骤③的具体过程为:
③-1、将当前正在处理的二维视频中的t时刻的视频帧{It(x,y)}定义为当前视频帧;
③-2、提取当前视频帧中的每个像素点的红颜色分量、绿颜色分量、蓝颜色分量、色调分量和饱和度分量,由提取出的每个像素点的红颜色分量、绿颜色分量、蓝颜色分量、色调分量和饱和度分量构成对应像素点的第一特征矢量,其中,当前视频帧中的每个像素点的第一特征矢量的维数为5×(W×H);
③-3、提取当前视频帧中的每个像素点经4个方向和3个尺度的可控金字塔滤波后得到的振幅,由提取出的每个像素点对应的12个振幅构成对应像素点的第二特征矢量,其中,当前视频帧中的每个像素点的第二特征矢量的维数为12×(W×H);
③-4、提取当前视频帧中的每个像素点经12个方向和3个尺度的Gabor滤波后得到的振幅,由提取出的每个像素点对应的36个振幅构成对应像素点的第三特征矢量,其中,当前视频帧中的每个像素点的第三特征矢量的维数为36×(W×H);
③-5、将当前视频帧中的每个像素点的第一特征矢量、第二特征矢量和第三特征矢量按序重组构成对应像素点的特征矢量,然后对当前视频帧中的所有像素点的特征矢量构成的矩阵进行低秩矩阵分解,得到当前视频帧中的所有像素点的特征矢量构成的矩阵的所有背景矩阵和所有运动矩阵;
③-6、利用最小化概率密度函数,获取当前视频帧中的所有像素点的特征矢量构成的矩阵的最优背景矩阵和最优运动矩阵,对应记为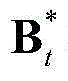 和
和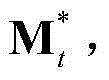 将
将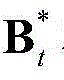 和
和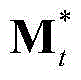 的组合记为
的组合记为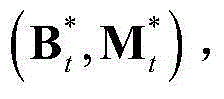 其中,F为当前视频帧中的所有像素点的特征矢量构成的矩阵,
其中,F为当前视频帧中的所有像素点的特征矢量构成的矩阵,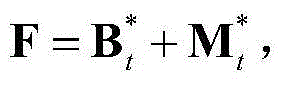 F、
F、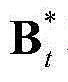 和
和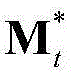 的维数均为53×(W×H),argmin[]表示最小化概率密度函数,Ωt表示对F进行低秩矩阵分解得到的所有的背景矩阵和运动矩阵的组合(Bt,Mt)的集合,(Bt,Mt)∈Ωt,符号“|| ||*”为求取矩阵核的范数符号,符号“|| ||1”为求取矩阵的1-范数符号,λ为拉格朗日乘子;
的维数均为53×(W×H),argmin[]表示最小化概率密度函数,Ωt表示对F进行低秩矩阵分解得到的所有的背景矩阵和运动矩阵的组合(Bt,Mt)的集合,(Bt,Mt)∈Ωt,符号“|| ||*”为求取矩阵核的范数符号,符号“|| ||1”为求取矩阵的1-范数符号,λ为拉格朗日乘子;
③-7、采用超像素分割技术将当前视频帧分割成M个互不重叠的区域,然后将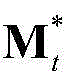 表示为其中,M≥1,
表示为其中,M≥1,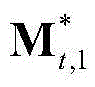 表示由
表示由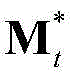 中属于第1个区域内的所有像素点的特征矢量构成的矩阵,
中属于第1个区域内的所有像素点的特征矢量构成的矩阵,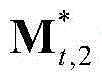 表示由
表示由 中属于第2个区域内的所有像素点的特征矢量构成的矩阵,
中属于第2个区域内的所有像素点的特征矢量构成的矩阵,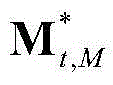 表示由
表示由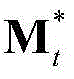 中属于第M个区域内的所有像素点的特征矢量构成的矩阵,
中属于第M个区域内的所有像素点的特征矢量构成的矩阵,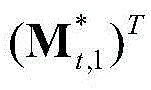 为
为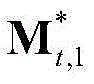 的转置矢量,
的转置矢量,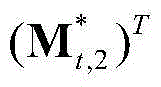 为
为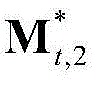 的转置矢量,
的转置矢量,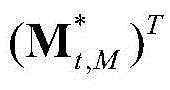 为
为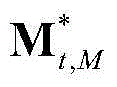 的转置矢量,
的转置矢量,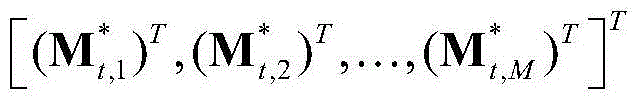 为
为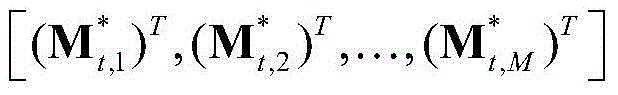 的转置矢量,符号“[]”为矢量表示符号;
的转置矢量,符号“[]”为矢量表示符号;
③-8、计算当前视频帧中的每个区域的空间显著值,将当前视频帧中的第k个区域的空间显著值记为ft,k,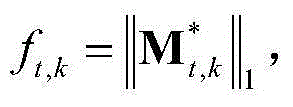 然后将当前视频帧中的每个区域的空间显著值作为对应区域内的所有像素点的空间显著值,得到当前视频帧中的每个像素点的空间显著值,从而得到当前视频帧的空间显著图,记为{St,spatial(x,y)},其中,1≤k≤M,
然后将当前视频帧中的每个区域的空间显著值作为对应区域内的所有像素点的空间显著值,得到当前视频帧中的每个像素点的空间显著值,从而得到当前视频帧的空间显著图,记为{St,spatial(x,y)},其中,1≤k≤M,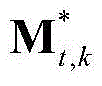 表示由
表示由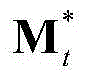 中属于第k个区域内的所有像素点的特征矢量构成的矩阵,St,spatial(x,y)表示{St,spatial(x,y)}中坐标位置为(x,y)的像素点的像素值;
中属于第k个区域内的所有像素点的特征矢量构成的矩阵,St,spatial(x,y)表示{St,spatial(x,y)}中坐标位置为(x,y)的像素点的像素值;
③-9、令t=t+1,将二维视频中下一个时刻的视频帧作为当前视频帧,然后返回步骤③-2继续执行,直至二维视频中的所有视频帧处理完毕,得到二维视频中每个时刻的视频帧的空间显著图,其中,t=t+1中的“=”为赋值符号。
所述的步骤③-6中取λ=0.06;所述的步骤③-7中取M=200。
所述的步骤④中取α=0.3。
与现有技术相比,本发明的优点在于:
1)本发明方法首先通过对二维视频在时域上、在水平方向及在垂直方向进行采样,分别得到X-Y截面图像、X-T截面图像和Y-T截面图像,然后通过对X-T截面图像和Y-T截面图像进行低秩矩阵分解提取出X-Y截面图像的运动显著图,对X-Y截面图像的特征矢量进行低秩矩阵分解提取出X-Y截面图像的空间显著图,最后对运动显著图和空间显著图进行融合,得到最终的视频显著图,所获得的视频显著图能够较好地反映视频的静态和动态区域的显著变化情况。
2)本发明方法采用低秩矩阵分解将图像分解为背景矩阵和运动矩阵,并从运动矩阵中提取出显著信息,这样能够提取符合人眼运动显著语义的特征信息,有效地提高了特征提取的鲁棒性,从而提高了视频显著图的提取精度。
附图说明
图1为本发明方法的总体实现框图;
图2a为“video5”视频序列的第100帧视频图像;
图2b为“video5”视频序列的第100帧视频图像的运动显著图;
图2c为“video5”视频序列的第100帧视频图像的空间显著图;
图2d为“video5”视频序列的第100帧视频图像的视频显著图;
图3a为“video8”视频序列的第100帧视频图像;
图3b为“video8”视频序列的第100帧视频图像的运动显著图;
图3c为“video8”视频序列的第100帧视频图像的空间显著图;
图3d为“video8”视频序列的第100帧视频图像的视频显著图;
图4a为“video10”视频序列的第100帧视频图像;
图4b为“video10”视频序列的第100帧视频图像的运动显著图;
图4c为“video10”视频序列的第100帧视频图像的空间显著图;
图4d为“video10”视频序列的第100帧视频图像的视频显著图;
图5a为“video21”视频序列的第100帧视频图像;
图5b为“video21”视频序列的第100帧视频图像的运动显著图;
图5c为“video21”视频序列的第100帧视频图像的空间显著图;
图5d为“video21”视频序列的第100帧视频图像的视频显著图。
具体实施方式
以下结合附图实施例对本发明作进一步详细描述。
本发明提出的一种视频显著图提取方法,其总体实现框图如图1所示,其包括以下步骤:
①由于二维视频可以看作是一个三维阵列即三维立方体,其在各个坐标轴上的语义特征是完全不一样的,因此本发明分别在时域上、在X方向上和在Y方向上进行采样,即对呈三维立方体的二维视频在时域上进行采样,得到二维视频的T个X-Y截面图像,即得到二维视频的T个时刻的视频帧,将二维视频中的t时刻的视频帧记为{It(x,y)},将{It(x,y)}中坐标位置为(x,y)的像素点的像素值记为It(x,y),其中,T表示二维视频中包含的视频帧的总帧数,1≤t≤T,1≤x≤W,1≤y≤H,W表示二维视频中各时刻的视频帧的宽,H表示二维视频中各时刻的视频帧的高。
同样,对呈三维立方体的二维视频在X方向上进行采样,得到二维视频的W个Y-T截面图像,将二维视频中的第x个Y-T截面图像记为{Ix(y,t)},将{Ix(y,t)}中坐标位置为(y,t)的像素点的像素值记为Ix(y,t),Ix(y,t)=It(x,y),即两者相等。
同样,对呈三维立方体的二维视频在Y方向上进行采样,得到二维视频的H个X-T截面图像,将二维视频中的第y个X-T截面图像记为{Iy(x,t)},将{Iy(x,t)}中坐标位置为(x,t)的像素点的像素值记为Iy(x,t),Iy(x,t)=It(x,y),即两者相等。
在三维立方体中,(x,y,t)是三维立方体中的任意点的坐标位置。
②由于Y-T截面图像和X-T截面图像包含了二维视频在垂直和水平方向的运动信息,因此本发明对二维视频中的每个Y-T截面图像进行低秩矩阵分解(low-rank matrixdecomposition),并获取二维视频中的每个Y-T截面图像的最优垂直方向运动矩阵,同样对二维视频中的每个X-T截面图像进行低秩矩阵分解,并获取二维视频中的每个X-T截面图像的最优水平方向运动矩阵;然后根据二维视频中的每个Y-T截面图像的最优垂直方向运动矩阵和每个X-T截面图像的最优水平方向运动矩阵,获取二维视频中每个时刻的视频帧的运动显著图,将二维视频中的t时刻的视频帧{It(x,y)}的运动显著图记为{St,motion(x,y)},其中,St,motion(x,y)表示{St,motion(x,y)}中坐标位置为(x,y)的像素点的像素值。
在此具体实施例中,步骤②的具体过程为:
②-1、对二维视频中的每个Y-T截面图像进行低秩矩阵分解,得到二维视频中的每个Y-T截面图像的所有垂直方向背景矩阵和所有垂直方向运动矩阵。
②-2、利用最小化概率密度函数,获取二维视频中的每个Y-T截面图像的最优垂直方向背景矩阵和最优垂直方向运动矩阵,将二维视频中的第x个Y-T截面图像{Ix(y,t)}的最优垂直方向背景矩阵和最优垂直方向运动矩阵对应记为 和
和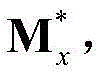 将
将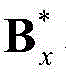 和
和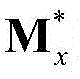 的组合记为
的组合记为 其中,Sx为二维视频中的第x个Y-T截面图像{Ix(y,t)}的矩阵形式表示,
其中,Sx为二维视频中的第x个Y-T截面图像{Ix(y,t)}的矩阵形式表示,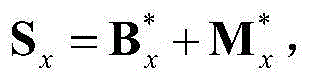 Sx、
Sx、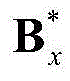 和
和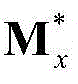 的维数均为H×T,argmin[]表示最小化概率密度函数,Ωx表示对Sx进行低秩矩阵分解得到的所有的垂直方向背景矩阵和垂直方向运动矩阵的组合(Bx,Mx)的集合,(Bx,Mx)∈Ωx,符号“|| ||*”为求取矩阵核的范数符号,符号“|| ||1”为求取矩阵的1-范数符号,λ为拉格朗日乘子,在本实施例中取λ=0.06。
的维数均为H×T,argmin[]表示最小化概率密度函数,Ωx表示对Sx进行低秩矩阵分解得到的所有的垂直方向背景矩阵和垂直方向运动矩阵的组合(Bx,Mx)的集合,(Bx,Mx)∈Ωx,符号“|| ||*”为求取矩阵核的范数符号,符号“|| ||1”为求取矩阵的1-范数符号,λ为拉格朗日乘子,在本实施例中取λ=0.06。
在本实施例中,采用鲁棒主成分分析方法求解最小化概率密度函数。
②-3、根据二维视频的W个Y-T截面图像各自的最优垂直方向运动矩阵,通过在X方向上进行叠加,构造得到Y-T截面图像的立方体,记为ScubeYT,其中,ScubeYT的维数为W×H×T。
②-4、对二维视频中的每个X-T截面图像进行低秩矩阵分解,得到二维视频中的每个X-T截面图像的所有水平方向背景矩阵和所有水平方向运动矩阵。
②-5、利用最小化概率密度函数,获取二维视频中的每个X-T截面图像的最优水平方向背景矩阵和最优水平方向运动矩阵,将二维视频中的第y个X-T截面图像{Iy(x,t)}的最优水平方向背景矩阵和最优水平方向运动矩阵对应记为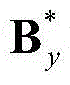 和
和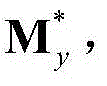 将
将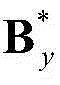 和
和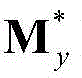 的组合记为
的组合记为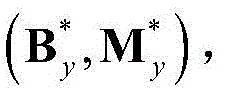 其中,Sy为二维视频中的第y个X-T截面图像{Iy(x,t)}的矩阵形式表示,
其中,Sy为二维视频中的第y个X-T截面图像{Iy(x,t)}的矩阵形式表示,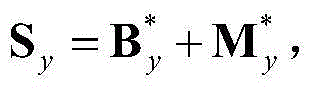 Sy、
Sy、 和
和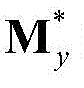 的维数均为W×T,Ωy表示对Sy进行低秩矩阵分解得到的所有的水平方向背景矩阵和水平方向运动矩阵的组合(By,My)的集合,(By,My)∈Ωy,在本实施例中取λ=0.06。
的维数均为W×T,Ωy表示对Sy进行低秩矩阵分解得到的所有的水平方向背景矩阵和水平方向运动矩阵的组合(By,My)的集合,(By,My)∈Ωy,在本实施例中取λ=0.06。
②-6、根据二维视频的H个X-T截面图像各自的最优水平方向运动矩阵,通过在Y方向上进行叠加,构造得到X-T截面图像的立方体,记为ScubeXT,其中,ScubeXT的维数为W×H×T。
②-7、计算norm(ScubeXT·*ScubeYT)作为二维视频的初步的运动显著图,其中,norm()表示归一化操作,norm(ScubeXT·*ScubeYT)中的符号“·*”为矩阵点乘符号。
②-8、采用高斯滤波器对二维视频的初步的运动显著图中每个时刻的X-Y截面图像进行平滑操作,得到二维视频中每个时刻的视频帧的运动显著图,将二维视频中的t时刻的视频帧{It(x,y)}的运动显著图记为{St,motion(x,y)},将{St,motion(x,y)}中坐标位置为(x,y)的像素点的像素值记为St,motion(x,y),St,motion(x,y)=S′t,motion(x,y)*Gσ(x,y),其中,S′t,motion(x,y)表示二维视频的初步的运动显著图中的t时刻的X-Y截面图像,“*”为卷积操作符号,Gσ(x,y)表示标准差为σ的高斯函数,在本实施例中取σ=5,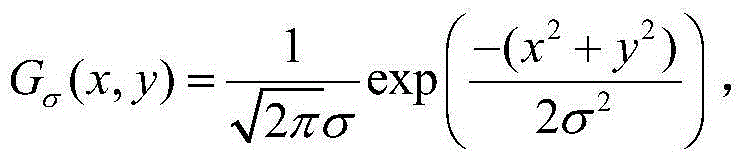 exp()为以e为底的指数函数,e表示自然基数,e=2.718281828。
exp()为以e为底的指数函数,e表示自然基数,e=2.718281828。
③由于静态场景也会吸引人的视觉注意力,但在静态场景中,各种运动几乎为零,无法采用基于运动的方法获得静态注意力区域,因此本发明方法提取二维视频中每个时刻的视频帧中的每个像素点的特征矢量;然后对提取得到的所有像素点的特征矢量构成的矩阵进行低秩矩阵分解,并获取二维视频中每个时刻的视频帧中的所有像素点的特征矢量构成的矩阵的最优背景矩阵和最优运动矩阵;再根据二维视频中每个时刻的视频帧中的所有像素点的特征矢量构成的矩阵的最优运动矩阵,获得二维视频中每个时刻的视频帧的空间显著图,将二维视频中的t时刻的视频帧{It(x,y)}的空间显著图记为{St,spatial(x,y)},其中,St,spatial(x,y)表示{St,spatial(x,y)}中坐标位置为(x,y)的像素点的像素值。
在此具体实施例中,步骤③的具体过程为:
③-1、将当前正在处理的二维视频中的t时刻的视频帧{It(x,y)}定义为当前视频帧。
③-2、提取当前视频帧中的每个像素点的红颜色分量、绿颜色分量、蓝颜色分量、色调分量和饱和度分量,由提取出的每个像素点的红颜色分量、绿颜色分量、蓝颜色分量、色调分量和饱和度分量构成对应像素点的第一特征矢量,其中,当前视频帧中的每个像素点的第一特征矢量的维数为5×(W×H)。
③-3、提取当前视频帧中的每个像素点经4个方向和3个尺度的可控金字塔(steerable pyramids)滤波后得到的振幅,由提取出的每个像素点对应的12个振幅构成对应像素点的第二特征矢量,其中,当前视频帧中的每个像素点的第二特征矢量的维数为12×(W×H)。
③-4、提取当前视频帧中的每个像素点经12个方向和3个尺度的Gabor滤波后得到的振幅,由提取出的每个像素点对应的36个振幅构成对应像素点的第三特征矢量,其中,当前视频帧中的每个像素点的第三特征矢量的维数为36×(W×H)。
③-5、将当前视频帧中的每个像素点的第一特征矢量、第二特征矢量和第三特征矢量按序重组构成对应像素点的特征矢量,然后对当前视频帧中的所有像素点的特征矢量构成的矩阵进行低秩矩阵分解,得到当前视频帧中的所有像素点的特征矢量构成的矩阵的所有背景矩阵和所有运动矩阵。
③-6、利用最小化概率密度函数,获取当前视频帧中的所有像素点的特征矢量构成的矩阵的最优背景矩阵和最优运动矩阵,对应记为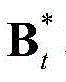 和
和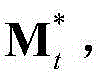 将
将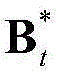 和
和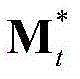 的组合记为
的组合记为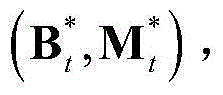 其中,F为当前视频帧中的所有像素点的特征矢量构成的矩阵,
其中,F为当前视频帧中的所有像素点的特征矢量构成的矩阵,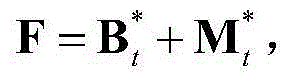 F、
F、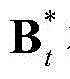 和
和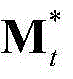 的维数均为53×(W×H),argmin[]表示最小化概率密度函数,Ωt表示对F进行低秩矩阵分解得到的所有的背景矩阵和运动矩阵的组合(Bt,Mt)的集合,(Bt,Mt)∈Ωt,符号“|| ||*”为求取矩阵核的范数符号,符号“|| ||1”为求取矩阵的1-范数符号,λ为拉格朗日乘子,在本实施例中取λ=0.06。
的维数均为53×(W×H),argmin[]表示最小化概率密度函数,Ωt表示对F进行低秩矩阵分解得到的所有的背景矩阵和运动矩阵的组合(Bt,Mt)的集合,(Bt,Mt)∈Ωt,符号“|| ||*”为求取矩阵核的范数符号,符号“|| ||1”为求取矩阵的1-范数符号,λ为拉格朗日乘子,在本实施例中取λ=0.06。
③-7、采用超像素(Superpixel)分割技术将当前视频帧分割成M个互不重叠的区域,然后将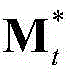 表示为其中,M≥1,
表示为其中,M≥1,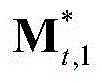 表示由
表示由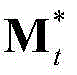 中属于第1个区域内的所有像素点的特征矢量构成的矩阵,
中属于第1个区域内的所有像素点的特征矢量构成的矩阵,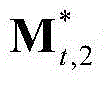 表示由
表示由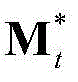 中属于第2个区域内的所有像素点的特征矢量构成的矩阵,
中属于第2个区域内的所有像素点的特征矢量构成的矩阵,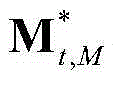 表示由
表示由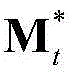 中属于第M个区域内的所有像素点的特征矢量构成的矩阵,
中属于第M个区域内的所有像素点的特征矢量构成的矩阵,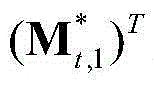 为
为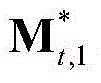 的转置矢量,
的转置矢量,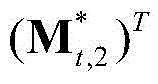 为
为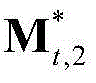 的转置矢量,
的转置矢量,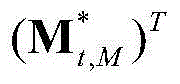 为
为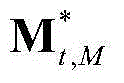 的转置矢量,
的转置矢量,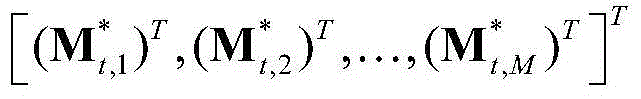 为
为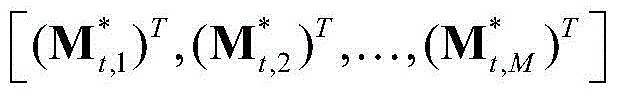 的转置矢量,符号“[]”为矢量表示符号,在本实施例中取M=200。
的转置矢量,符号“[]”为矢量表示符号,在本实施例中取M=200。
③-8、计算当前视频帧中的每个区域的空间显著值,将当前视频帧中的第k个区域的空间显著值记为ft,k,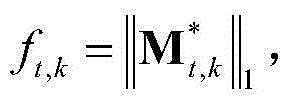 然后将当前视频帧中的每个区域的空间显著值作为对应区域内的所有像素点的空间显著值,得到当前视频帧中的每个像素点的空间显著值,从而得到当前视频帧的空间显著图,记为{St,spatial(x,y)},其中,1≤k≤M,
然后将当前视频帧中的每个区域的空间显著值作为对应区域内的所有像素点的空间显著值,得到当前视频帧中的每个像素点的空间显著值,从而得到当前视频帧的空间显著图,记为{St,spatial(x,y)},其中,1≤k≤M,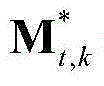 表示由
表示由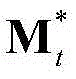 中属于第k个区域内的所有像素点的特征矢量构成的矩阵,St,spatial(x,y)表示{St,spatial(x,y)}中坐标位置为(x,y)的像素点的像素值。
中属于第k个区域内的所有像素点的特征矢量构成的矩阵,St,spatial(x,y)表示{St,spatial(x,y)}中坐标位置为(x,y)的像素点的像素值。
③-9、令t=t+1,将二维视频中下一个时刻的视频帧作为当前视频帧,然后返回步骤③-2继续执行,直至二维视频中的所有视频帧处理完毕,得到二维视频中每个时刻的视频帧的空间显著图,其中,t=t+1中的“=”为赋值符号。
④对二维视频中每个时刻的视频帧的运动显著图和空间显著图进行融合,得到二维视频中每个时刻的视频帧的视频显著图,将二维视频中t时刻的视频帧{It(x,y)}的视频显著图记为{Svideo(x,y)},将{Svideo(x,y)}中坐标位置为(x,y)的像素点的像素值记为Svideo(x,y),Svideo(x,y)=(St,motion(x,y))α×(St,spatial(x,y))1-α,其中,α为权重系数,在本实施例中取α=0.3。
以下就利用本发明方法对比利时蒙斯理工学院TCTS实验室提供的ASCMN数据库中video5、video8、video10和video21四个视频序列的视频显著图进行提取。图2a给出了“video5”视频序列的第100帧视频图像,图2b给出了“video5”视频序列的第100帧视频图像的运动显著图,图2c给出了“video5”视频序列的第100帧视频图像的空间显著图,图2d给出了“video5”视频序列的第100帧视频图像的视频显著图;图3a给出了“video8”视频序列的第100帧视频图像,图3b给出了“video8”视频序列的第100帧视频图像的运动显著图,图3c给出了“video8”视频序列的第100帧视频图像的空间显著图,图3d给出了“video8”视频序列的第100帧视频图像的视频显著图;图4a给出了“video10”视频序列的第100帧视频图像,图4b给出了“video10”视频序列的第100帧视频图像的运动显著图,图4c给出了“video10”视频序列的第100帧视频图像的空间显著图,图4d给出了“video10”视频序列的第100帧视频图像的视频显著图;图5a给出了“video21”视频序列的第100帧视频图像,图5b给出了“video21”视频序列的第100帧视频图像的运动显著图,图5c给出了“video21”视频序列的第100帧视频图像的空间显著图,图5d给出了“video21”视频序列的第100帧视频图像的视频显著图。从图2a至图5d可以看出,采用本发明方法得到的视频显著图由于考虑了空间显著图和运动显著图,因此能够较好地反映视频的静态和动态的显著变化情况,符合视频显著语义的特征。
